
Benchmarking AI Agents on Long-Horizon Single-Cell Biology
A verifiable benchmark for recovering scientific conclusions from raw single-cell data

Practical tasks in single-cell biology require complex analysis workflows, multiple sources of assay data and creative thinking in the context of prior literature.
Agents for biology research are rapidly improving. But integrating them into productive R&D workflows requires rigorous measurement of capability.
We introduce scBench-Long, a benchmark for long-horizon single-cell biology in which agents must recover scientific conclusions from raw or near-raw data without prescribed methods.
The benchmark contains 21 evaluations spanning melanoma CD8 T-cell reactivity, CD8 RNA+ATAC regulatory inference, human-monkey chimera development, KRAS-driven lung tumor aging, and lethal COVID-19 lung pathology. Across 1,068 completed trajectories, the strongest agent systems pass 16/63 runs (25.4%).
View the results, including interactive agent trajectory viewers, at benchmarks.bio. Read the full manuscript.
Motivation
Agentic AI-biology benchmarks have made rapid progress, but most focus on broad biological knowledge. Existing single-cell benchmarks focus on local analysis steps and do not evaluate realistic long-horizon science.
scBench-Long tests whether agents can move beyond accurately performing local analysis steps to reasoning about the kinds of realistic scientific tasks found in published studies or used in drug programs.
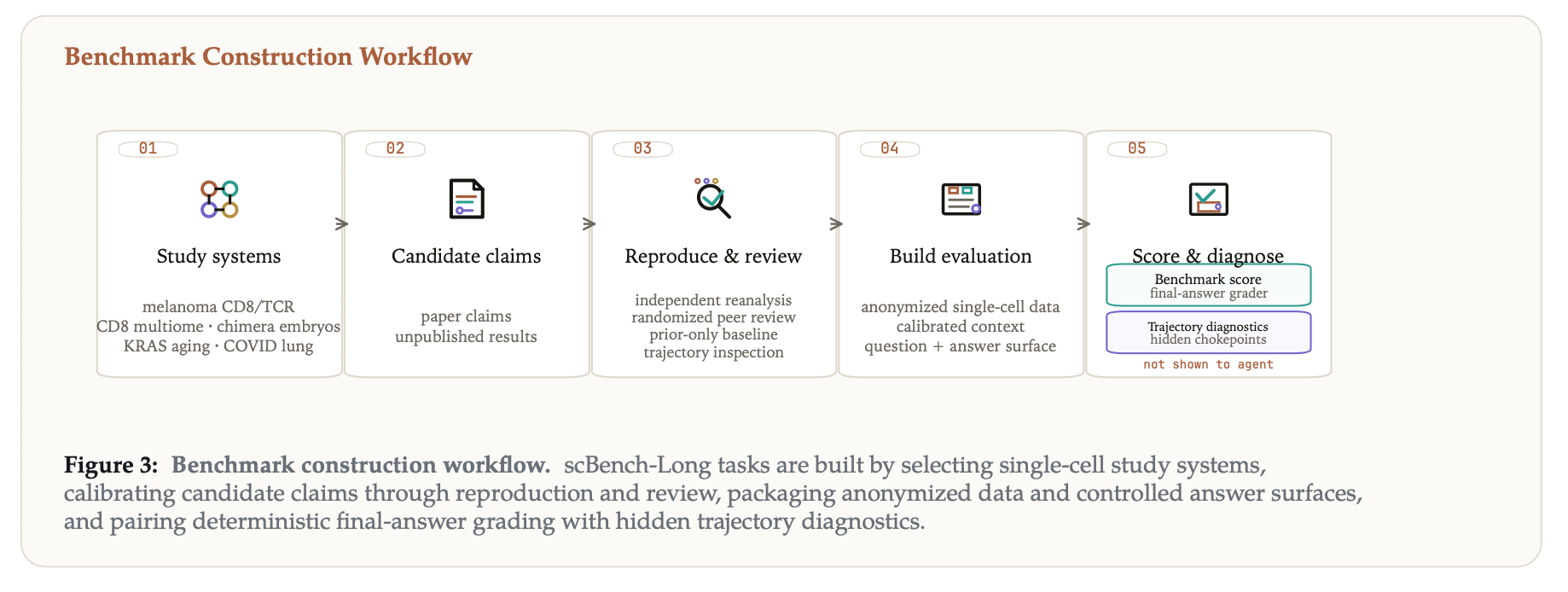
The benchmark builds on prior claim-conditioned benchmark construction rather than introducing a new general grading framework.
Each evaluation includes:
Raw or near-raw data
A task description: calibrated experimental context, anonymized labels where needed and a compact scientific question
A controlled final-answer vocabulary, often consisting of cell or gene markers and symbols for directionality
Reproduction notes
Trajectory rubrics
Paper claims are used as sources for candidate evaluations, not as automatic ground truth. Candidate tasks are retained only when the target conclusion can be reproduced from the staged data and hardened through review, distractor design, and inspection of trajectories from multiple model families.
Main Results
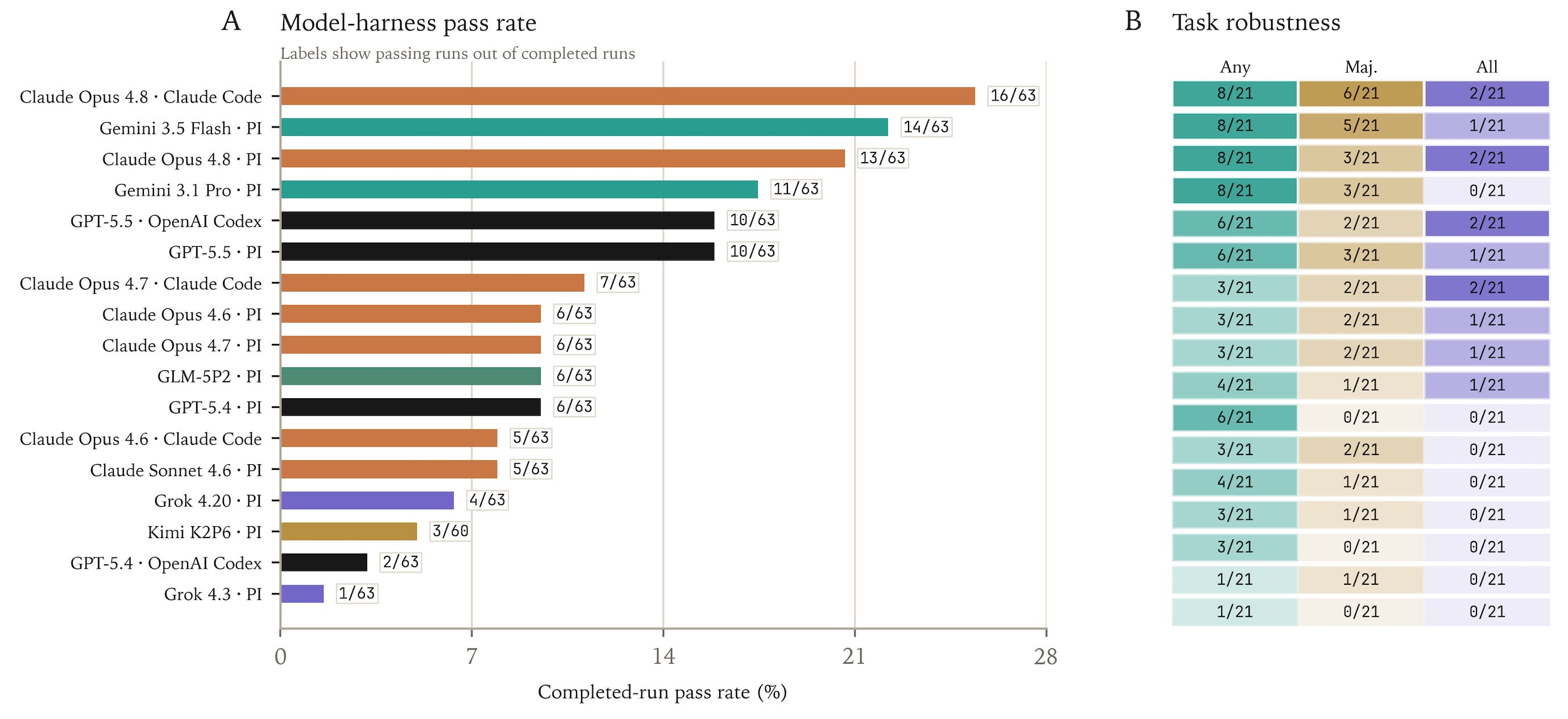
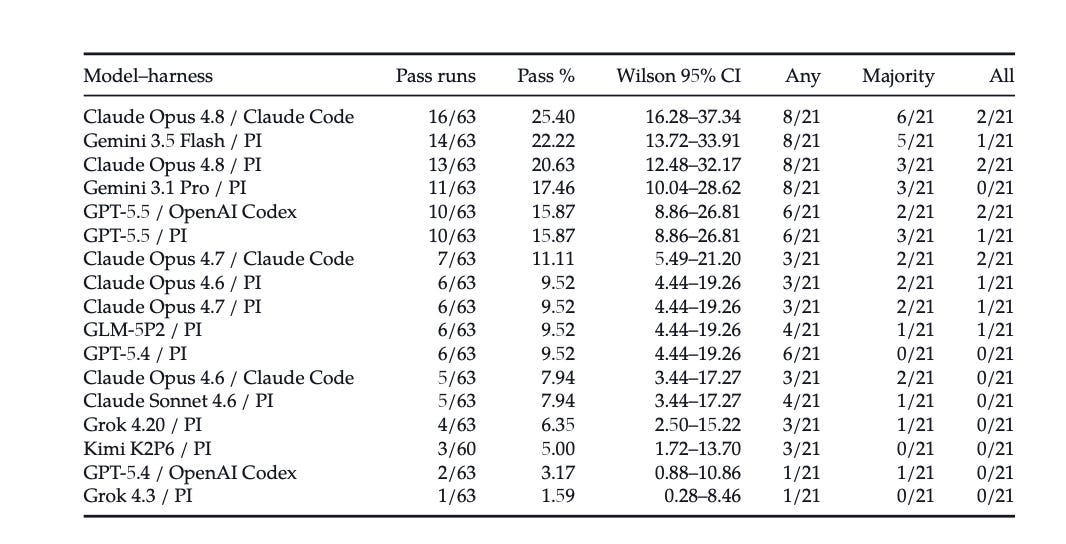
We evaluated 17 model-harness configurations across 21 final evaluations, producing 1,068 completed trajectories. Scores use deterministic pass/fail grading of the final structured answer.
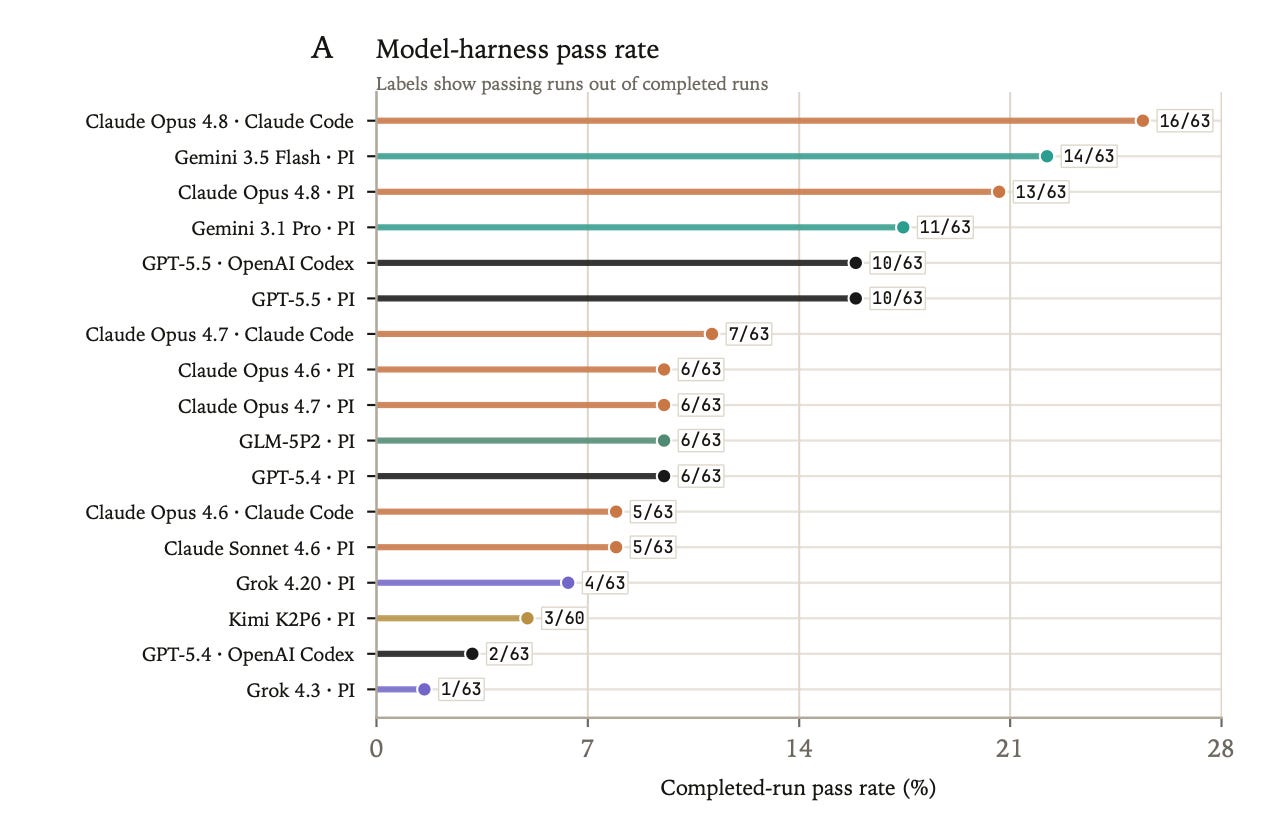
The strongest model-harness pair was Claude Opus 4.8 with Claude Code, which passed 16/63 runs, or 25.4%. Gemini 3.5 Flash with PI followed at 14/63, or 22.2%. GPT-5.5 reached 10/63 under both OpenAI Codex and PI, but the two harnesses solved different evaluations.
Trajectory Diagnostics
Endpoint grading is stable and reproducible, but it is sparse. A model can fail the final answer while completing many useful intermediate steps. To understand this partial progress, scBench-Long also includes task-specific trajectory rubrics scored by multiple judge models.
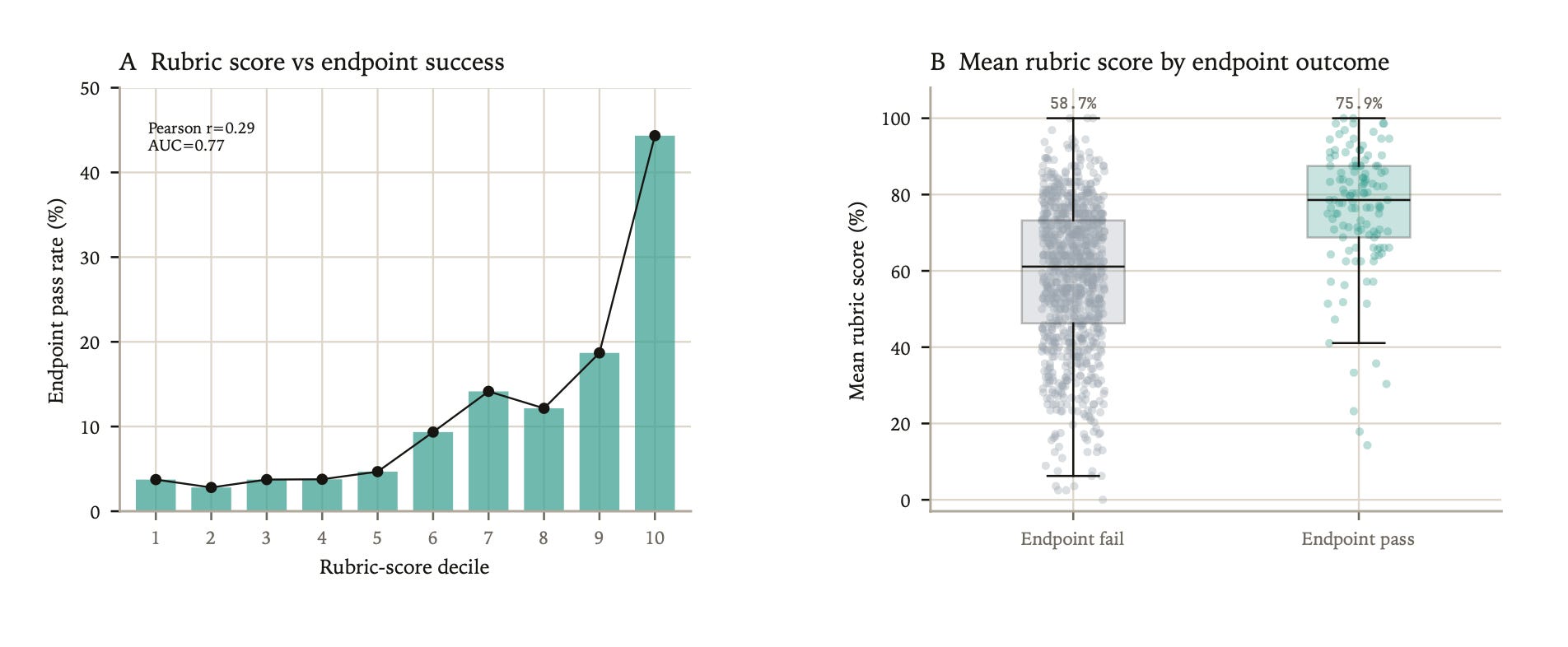
Rubric scores are useful but imperfect. Endpoint-passing trajectories had higher mean rubric scores than endpoint-failing trajectories: 75.9% versus 58.7%. The highest rubric-score decile was enriched for success, but still contained many endpoint failures. Deterministic final-answer grading remains our preferred method of reporting benchmark results, while rubric judges are used as diagnostic instruments.
Common Failure Modes
The most interesting failures were gaps in scientific reasoning where agents frequently found correct intermediate results - cell populations, plausible ligand-receptor interactions, immune receptor patterns, or regulatory programs - but did not assemble them into the correct biological claim.
Some recurring patterns:
Familiar biological priors can override evidence in the actual data. In melanoma CD8 tasks, agents often relied on markers such as CD39, PD-1, TOX, LAG3, HAVCR2, and CXCL13 instead of combining physical tumor/APC engagement with paired TCR clonal expansion.
Raw abundance can be mistaken for biological importance. In a human-monkey chimera ligand-receptor task, agents often selected the largest raw interaction class even though no single signaling family dominated after accounting for directionality and database composition.
Molecular association can be mistaken for mechanism. In tumor-T-cell conjugate tasks, agents identified enriched tumor programs but treated co-occurrence after physical pairing as evidence for a directional mechanism.
Agents fail to reason across modalities and rely on eg. RNA alone. CD8 RNA+ATAC tasks required checking if RNA-level regulator patterns were consistent with chromatin accessibility data.
Harnesses Matter
scBench-Long evaluates “agent systems”: model-harness pairs. The harness can have a surprising effect on the performance of the underlying base model.
Claude Opus 4.8 performed better with Claude Code than PI: 16/63 versus 13/63. GPT-5.4 performed better with PI than OpenAI Codex: 6/63 versus 2/63. GPT-5.5 had the same aggregate pass rate under OpenAI Codex and PI, but solved different evaluations and had different task-level robustness.
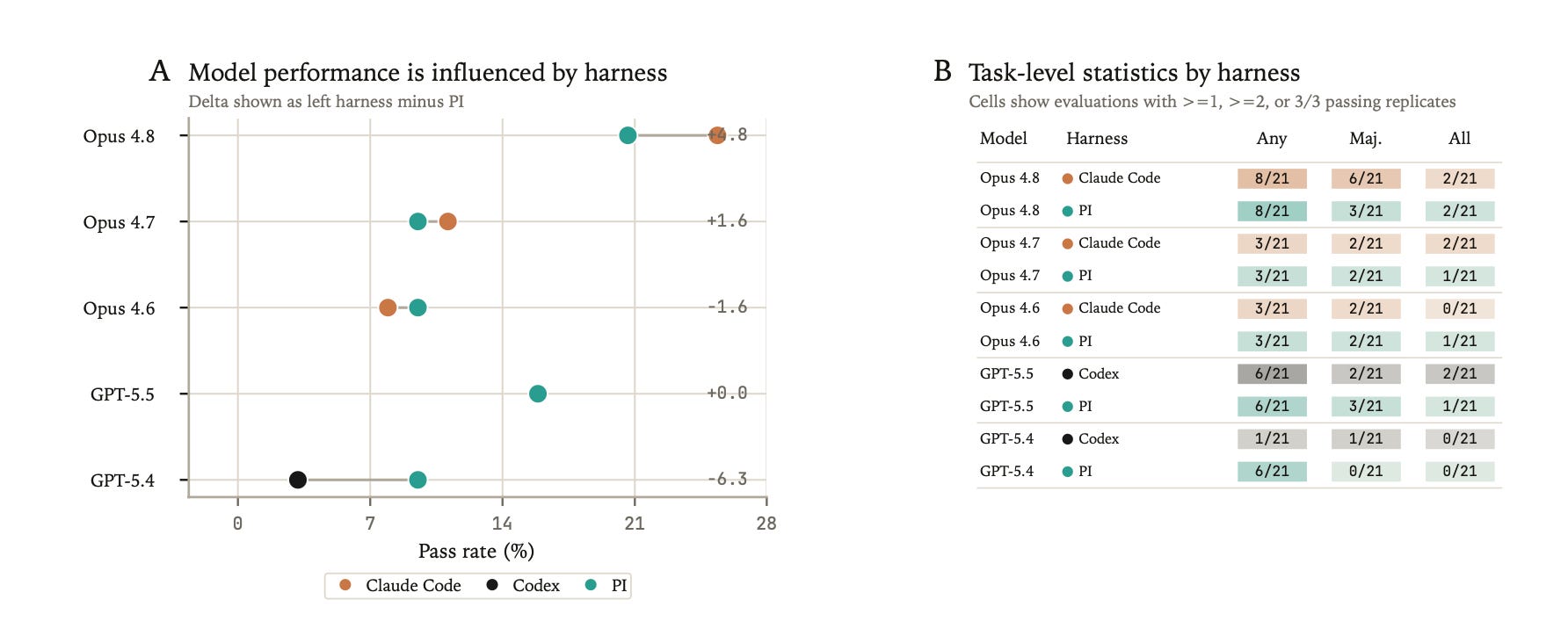
The harness affects how the model searches, writes code, inspects intermediate files, recovers from mistakes, etc. We found open source harnesses with fewer tools encourage more efficient (time + cost) trajectories in science.
Toward Reliable Long Horizon Biology Agents
We hope scBench-Long serves both as a measurement tool and a diagnostic lens for developing agents that analyze single-cell data faithfully, transparently, and reproducibly.
It is a focused contribution within a broader benchmark family spanning major biological data classes and work categories, including spatial biology, epigenomics, and therapeutics.
More broadly, we view benchmarks as evolving specifications of computational biology workflows, supporting test-driven development of agent systems whose behavior can improve through both model training and harness engineering.
Manuscript: latch.bio/scbench-long
Leaderboard: benchmarks.bio
The failure taxonomy is what makes this land, most benchmark writeups bury the failures and you led with them. What your list made me realize is that none of the four modes are really AI-specific.
Priors overriding the data, abundance read as importance, association slid into mechanism, single-modality shortcuts, those are the same traps that produce shaky claims in the human single-cell literature too. So the benchmark almost reads as a catalog of the field's own reasoning habits, with the agents tripping in recognizably human ways.