
Benchmarking AI Agents on Small-Molecule Preclinical Pharmacology
A verifiable benchmark for practical decisions about potency, mechanism, exposure, safety, and efficacy

We introduce TherapeuticsBench Preclinical Pharmacology (TxBench-PP), a verifiable benchmark for small-molecule preclinical pharmacology and the first focused slice of a broader TherapeuticsBench effort across drug-discovery stages and therapeutic modalities.
TxBench-PP tests whether agents can recover accurate conclusions from realistic assay artifacts rather than memorized facts from the literature. The benchmark contains 100 evaluations indexed by program stage, assay type, and task structure, spanning mechanism-of-action (MoA) and pharmacodynamic (PD) reasoning, compound-target engagement, causal target validation, developability and safety, and translational efficacy.

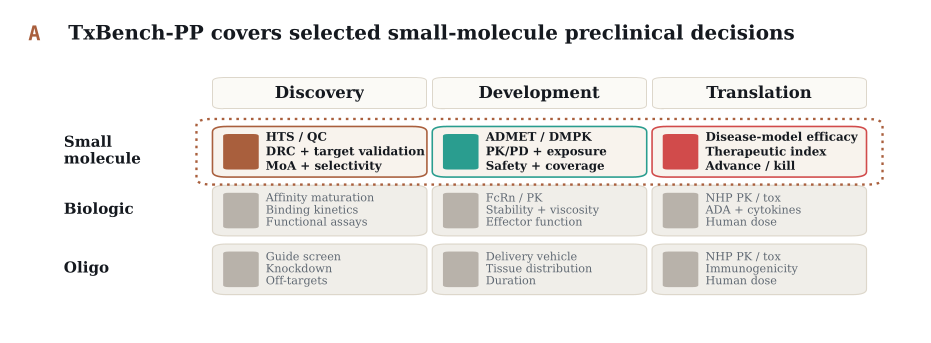
The strongest configuration was Claude Opus 4.8 + Pi at 59.3%, followed by GPT-5.5 + Pi at 55.3%.
Motivation
While experiments are rate-limited by natural processes, human decisions and organizational consensus often make up significant components of program timelines in drug discovery. Agents promise to accelerate discovery, development, and translation by compressing these interpretation and decision-making loops.
However, the practical use of agentic systems in industrial workflows requires standardized and trusted methods of evaluating performance. This is especially challenging in drug discovery because the ecosystem is a sprawling landscape of assay categories, development stages, therapeutic modalities, and decision types. Benchmarks must therefore measure realistic tasks while providing focused treatment of the many local scientific judgments that make up the biotech ecosystem.
Main Results
We evaluated 16 model-harness configurations, comprising 11 models across three agent harnesses, on 100 preclinical pharmacology tasks. Each configuration was run three independent times per task, yielding 4,800 agent trajectories. The strongest configuration was Claude Opus 4.8 + Pi at 59.3%, followed by GPT-5.5 + Pi at 55.3%, Claude Opus 4.8 + Claude Code at 54.7%, and Gemini 3.5 Flash + Pi at 51.3%.
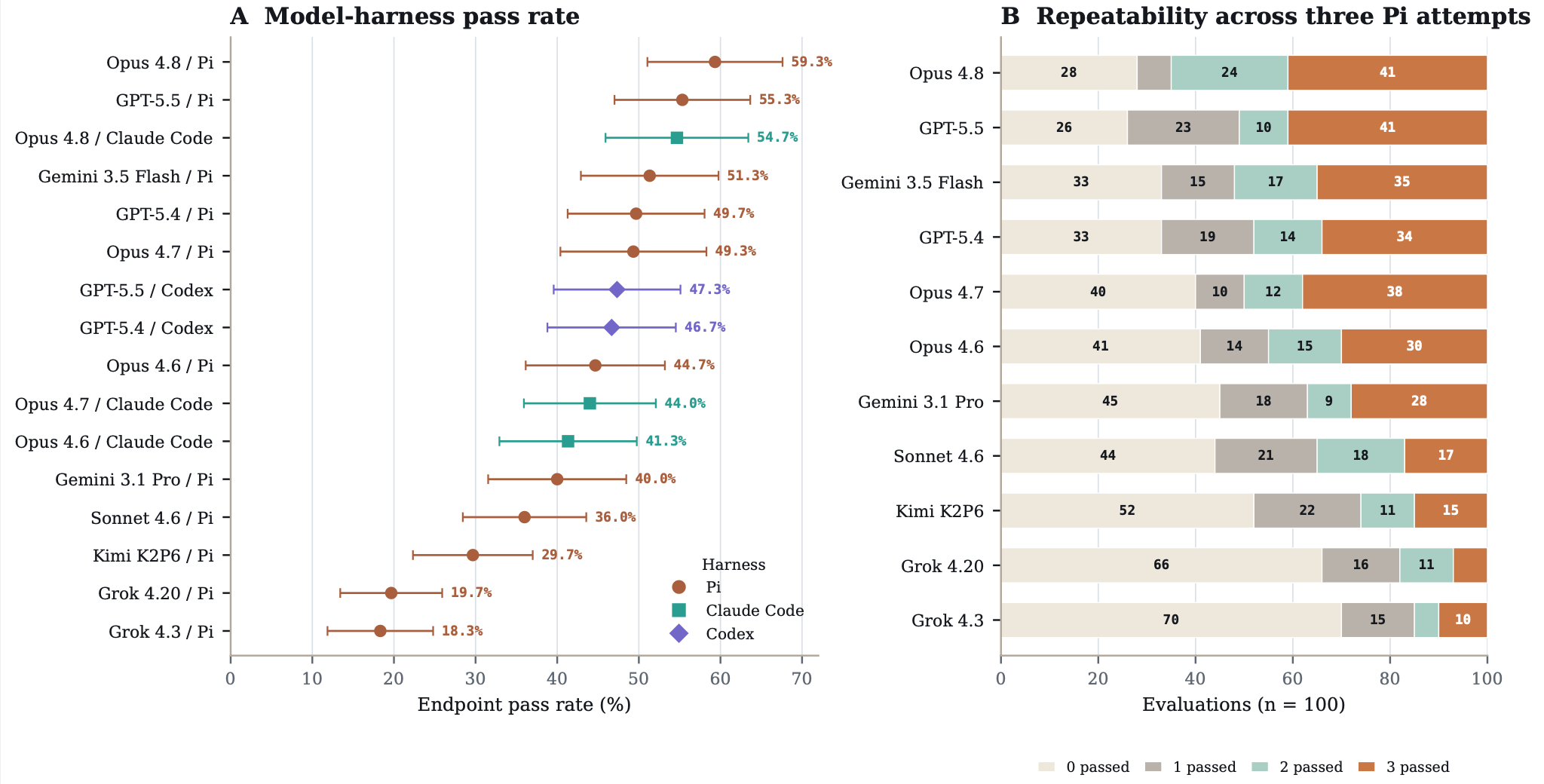
Trajectory analysis reveals gaps in scientific judgement
We manually reviewed 1,834 failing Pi-harness trajectories. Most failures reflected substantive gaps in scientific judgment, where models inspected data and performed plausible analyses but ultimately reached incorrect conclusions. Failures included incorrect perception of assay outputs, reliance on literature priors over supplied evidence, and assay-specific reasoning mistakes.
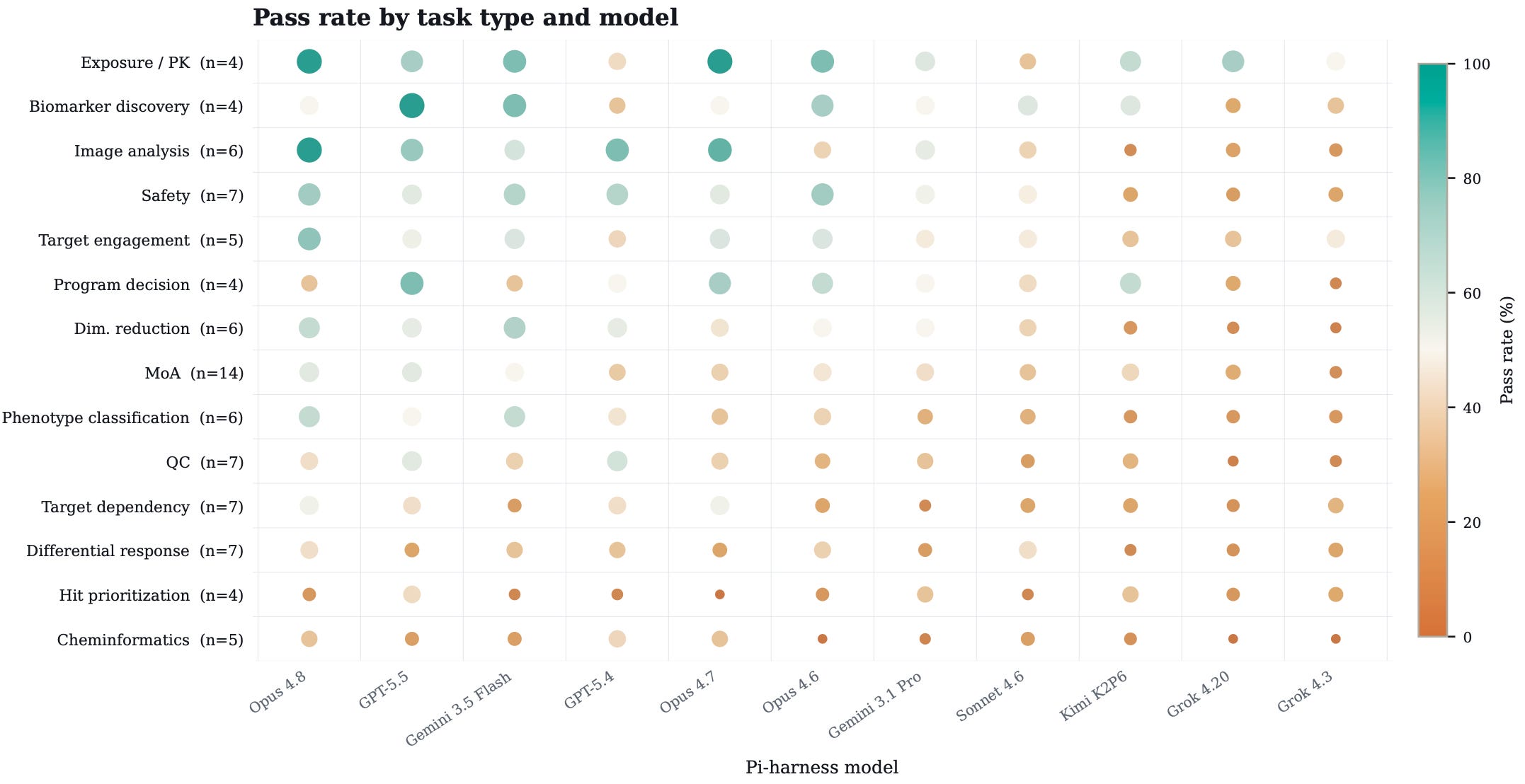
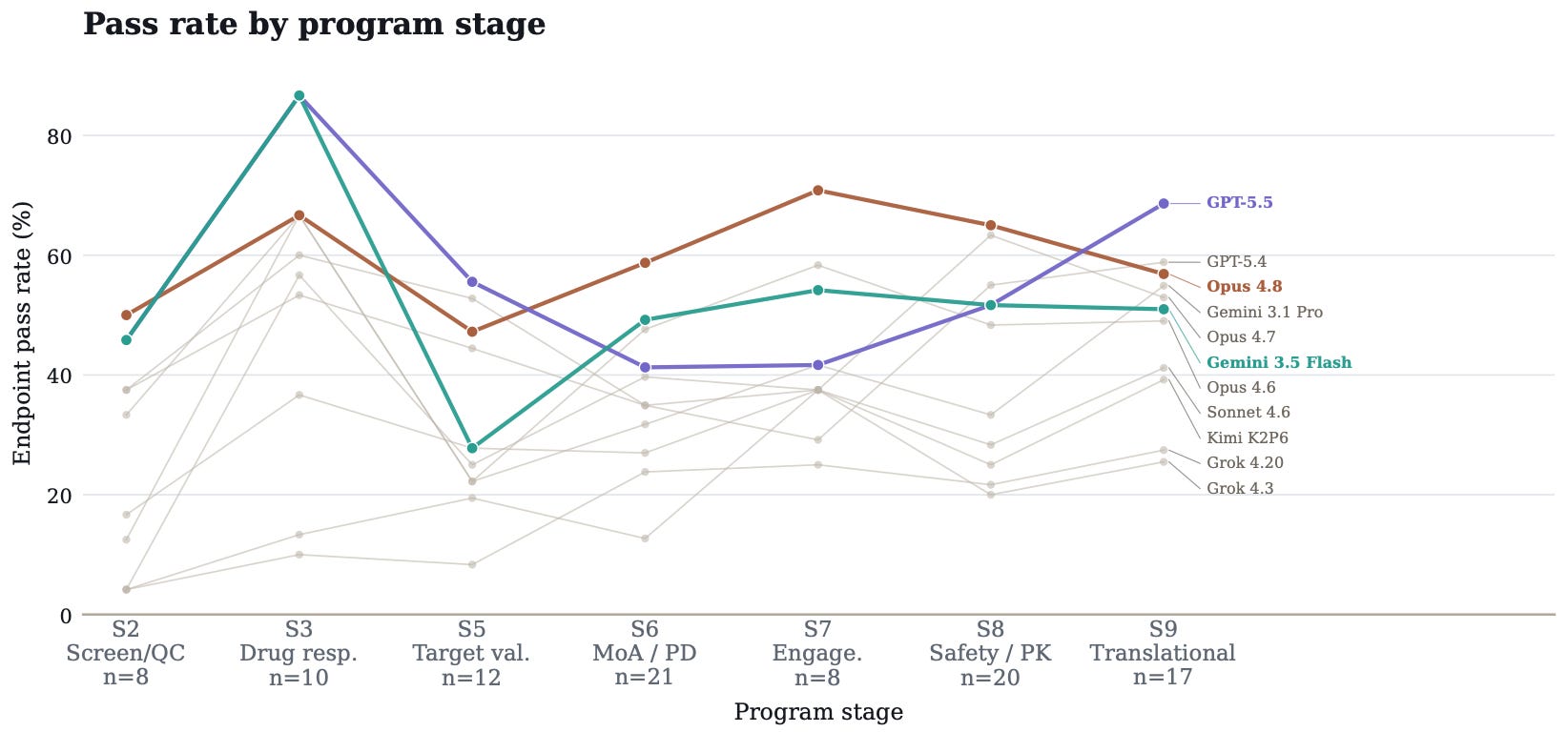
Performance varied by program stage
Model accuracy ranged from 27% in screening and hit prioritization to 55% in drug response. Difficult program stages involved decisions across QC, statistics, and chemical or biological judgment of molecular candidates.
View results and subset of evals/trajectories
Read the manuscript for more development: latch.bio/txbench-pp.
We regularly update our benchmark family with new models: benchmarks.bio.
Encourage those interested in understanding what these benchmarks actually measure to inspect sample tasks and trajectories.