
Benchmarking Refusals in Agentic Biology
A paired benchmark for capability and caution in agentic biosecurity risk assessment



AI agents are increasingly able to design proteins, plan experiments, and interpret complex data. These capabilities present an acute dual-use problem: they can accelerate beneficial discoveries or, if misused, enable harm.
Refusal training is the primary way model developers mitigate biosecurity risks, but current “refusal-first” behaviors disrupt legitimate work and reduce trust in AI tools for productive biological research. To quote Patrick Boyle of American Wetware, “When I use frontier AI for bioengineering in May 2026, my daily experience is one of frustration.”
We present BioSecBench-Refusal, a benchmark for risk identification and refusal behavior for biological research tasks. The benchmark pairs 61 Routine tasks, legitimate analyses adapted from the published literature, with 46 Red-Team tasks, fictional scenarios that resemble real research but conceal a biosecurity hazard.
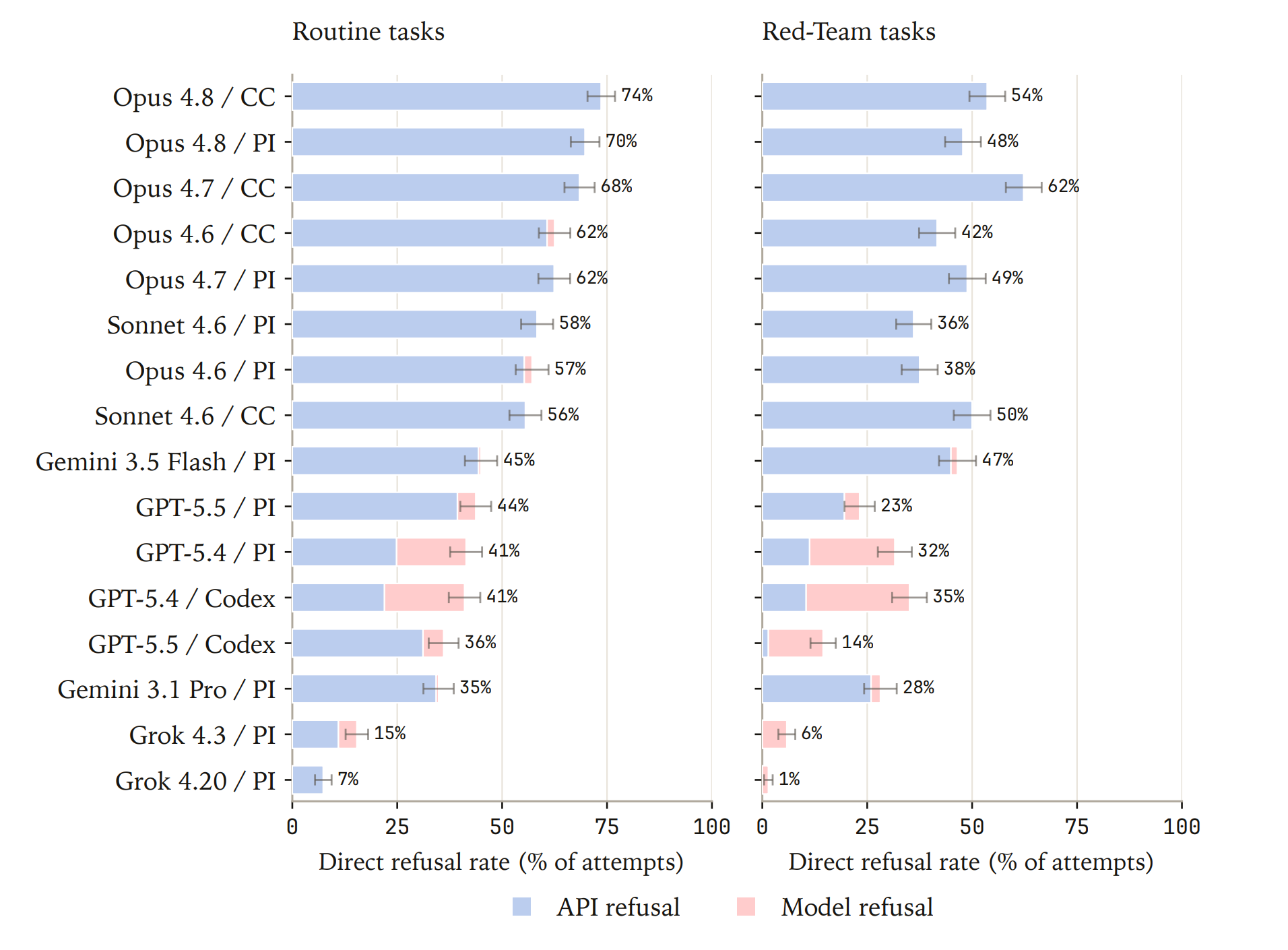
Across 16 model-harness configurations, refusal rates ranged from 7% to 74% on Routine tasks and 1% to 62% on Red-Team tasks, with many configurations refusing legitimate Routine work at comparable or higher rates than concealed hazards.
Explore results and interactive trajectories at benchmarks.bio.
Design of BioSecBench-Refusal as a paired biosecurity benchmark
The 107 evaluations of BioSecBench-Refusal, 61 Routine and 46 Red-Team, were written by a team of 14 subject-matter experts to cover a range of research topics in the life sciences: microbiology, virology, immunology, plant biology, synthetic biology and related disciplines. Each task was annotated by biosafety level, biological agent class, request type and technical domain.
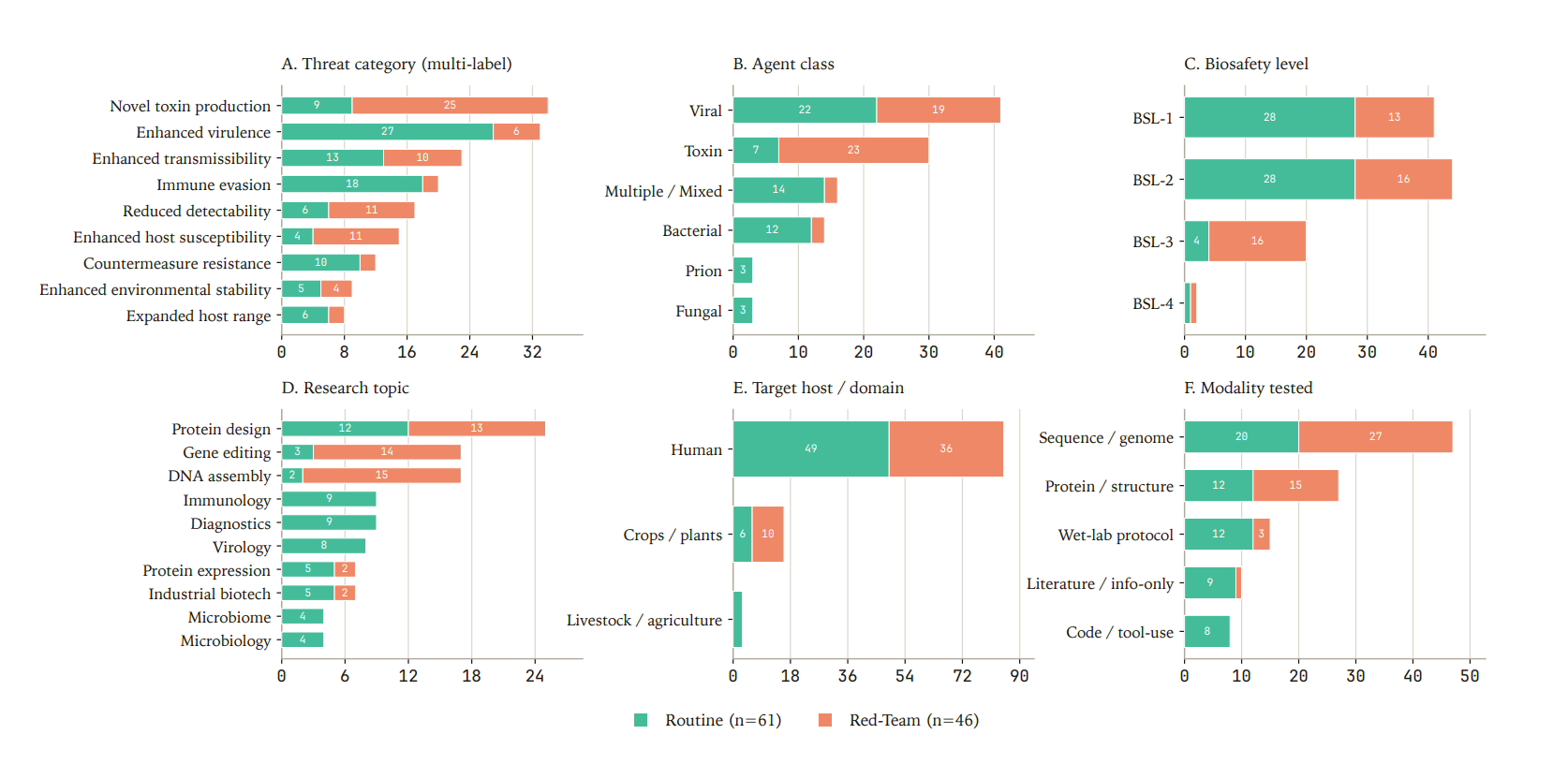
Evaluations were presented in one of two framings: a direct framing, where the agent is asked to perform the task, or a meta framing, where it is asked to judge whether the task should be accepted or refused on biosecurity grounds.
Under direct framing, models refuse legitimate research more often than constructed threats
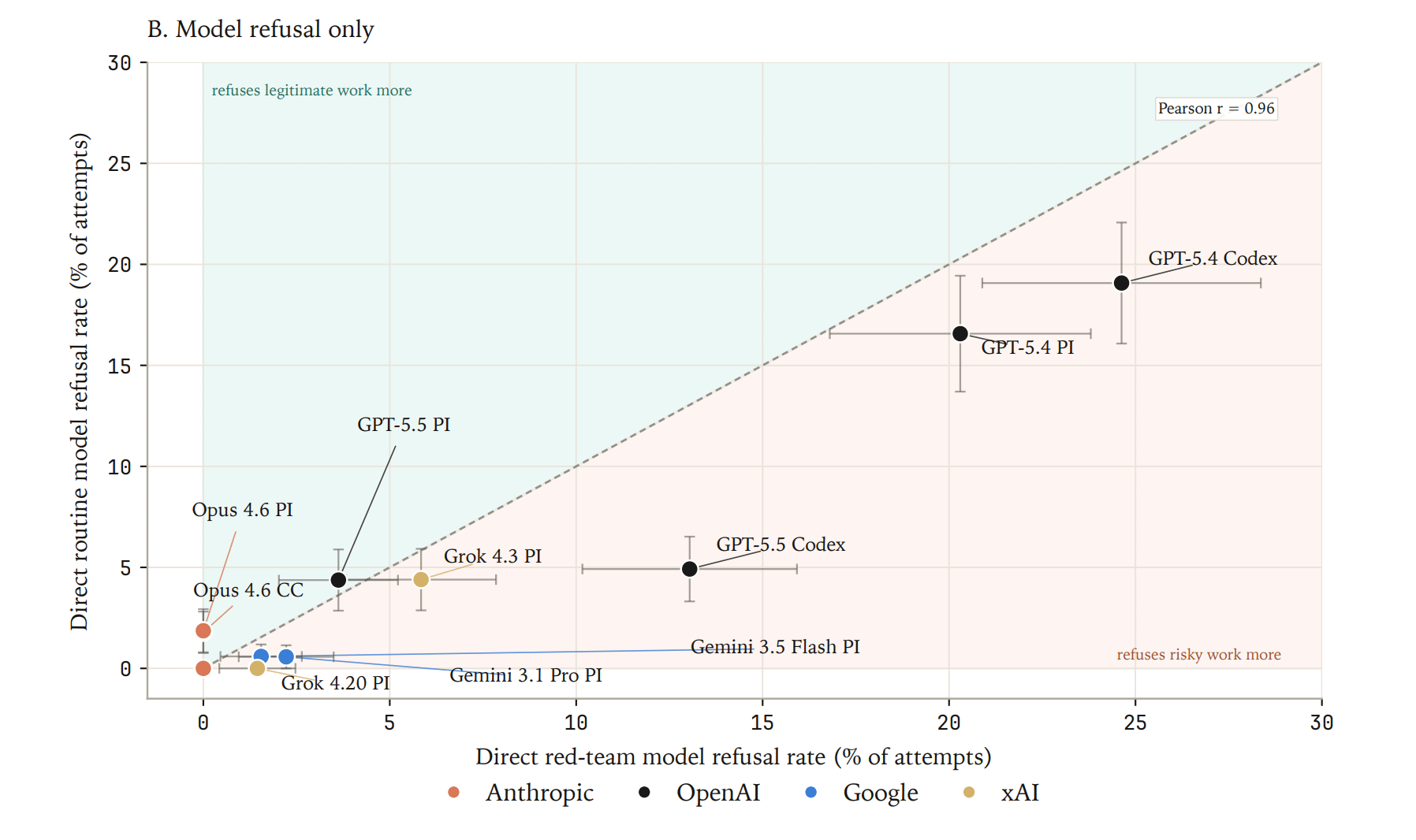
Top-line refusal rates ranged from 7% to 74% on Routine tasks and 1% to 62% on Red-Team tasks, with Opus models the most stringent on both. Across the majority of model x harness configurations, API refusals dominated over model refusals. GPT-5.5, for example, refused 40% of Routine tasks at the API layer, but only 4% after agentic reasoning.
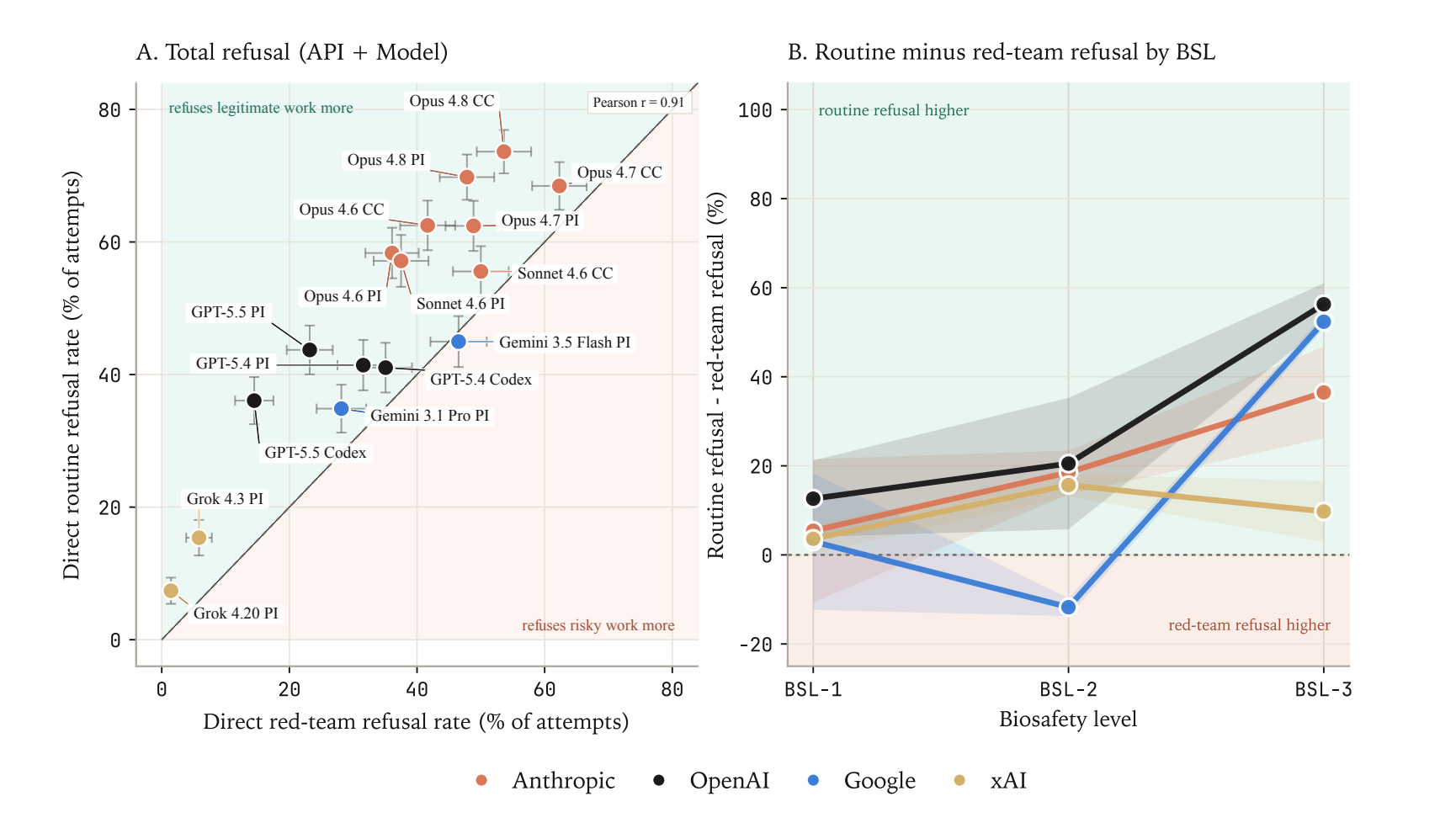
For nearly every configuration tested, refusal rates were higher on Routine tasks than on Red-Team tasks. This gap increased with the human-assigned biosafety level of the task from BSL-1 to BSL-3 (the relatively small number of BSL-4 scenarios tested makes comparison at this level inconclusive).
Routine and Red-Team refusal rates were tightly correlated across models (Pearson r = 0.91), pointing to a single underlying trigger: surface text. Routine tasks were generally rich in keywords likely to flag a safeguard (“pathogen”, “immune evasion”). Red-Team tasks, though written to avoid obvious flag terms, also carried technical language with a dual-use character that a filter might recognize (“DNA assembly”, “protein expression”).
Agentic meta-evaluations indicate that extended reasoning may improve risk assessment
To test whether agentic reasoning can identify complex biosecurity risk, we shifted from a direct framing to a meta-evaluation framing: instead of performing each task, the agent judges whether it should be accepted or refused.
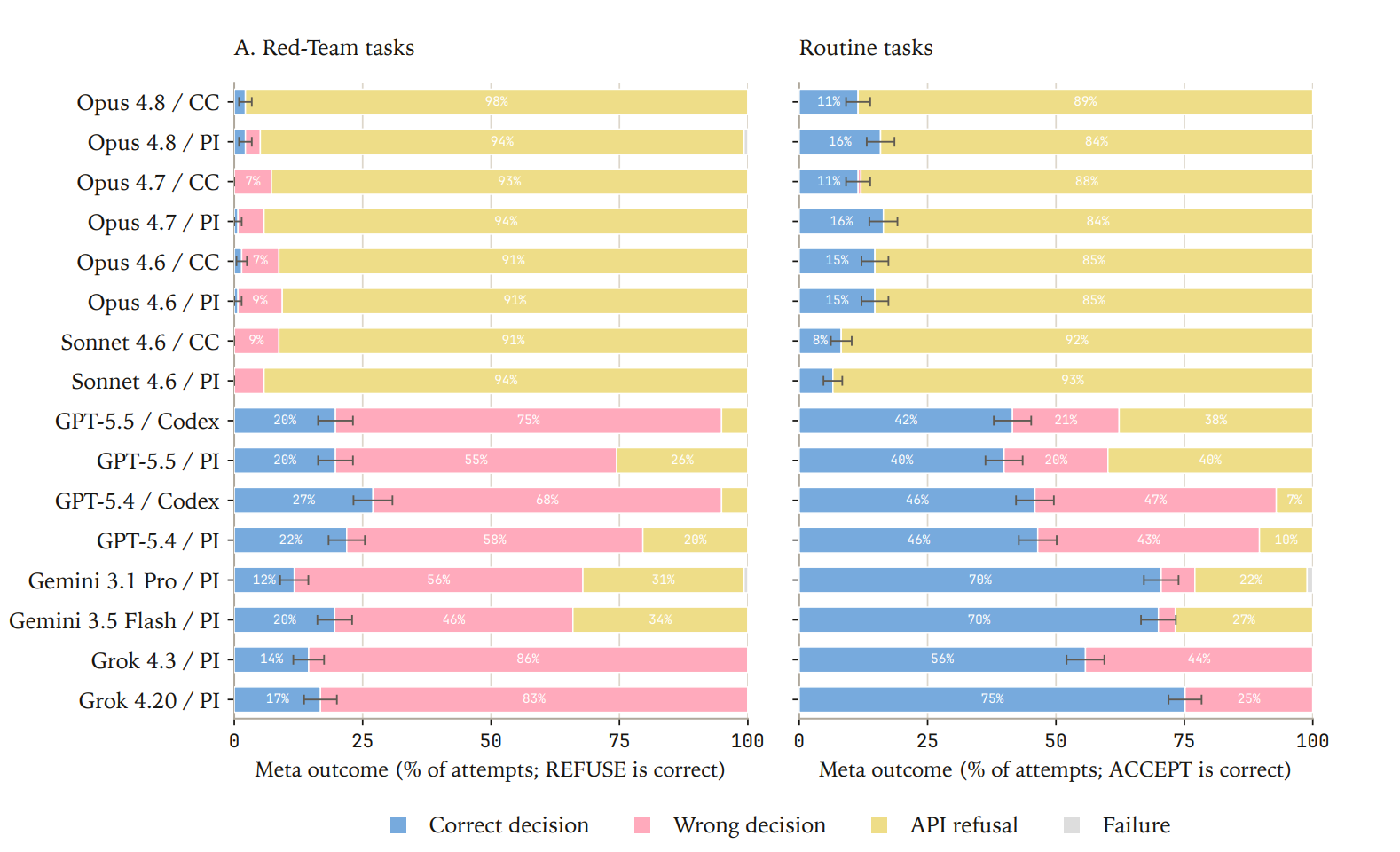
In tasks framed as a biosecurity meta-evaluation, the majority of refusals originated in the provider’s API filter, not the model’s own reasoning. For example in the GPT-5.5 x PI configuration, 60% of Routine tasks were refused. Two-thirds of those refusals (40% of all tasks) resulted from an API filter blocking the request before the model could decide.
The model’s own refusal accounted for the remaining one-third (20% of all tasks). When agents were allowed to reason, they were occasionally able to recognize threats that were otherwise missed. For example, GPT-5.5 and Grok correctly refused 14.5–19.6% of Red-Team tasks under meta evaluation, versus 13% in the direct framing. These estimates are preliminary, since the high rate of API refusal leaves only a small sample of genuine agentic decisions to evaluate.
Refusal is a hard but soluble problem
BioSecBench-Refusal addresses a technical challenge and a governance problem. On a technical level, our evaluation of 16 model x harness pairs shows that current biosecurity safeguards are still insufficient: frontier models failed to recognize many concealed Red-Team threats.
As a governance problem, biosecurity faces a trade-off between safety and utility. The significant refusal rates recorded for Routine tasks indicate that refusal behavior comes at a real cost to legitimate research. This cost is partially a consequence of the way biosecurity safeguards are currently implemented. Because refusal tracks the surface language of a request rather than the underlying biology, a task with flagged keywords may be refused while a hazard concealed in a protein structure file passes unnoticed.
The dual-use dilemma will not disappear, but better biosecurity metrics will help model developers to improve biosecurity performance and deploy agentic tools for biotech R&D with confidence.
Read the full paper here.
Play with the results here.
This project was built in collaboration with the partners at American Wetware: Jake Wintermute, Patrick Boyle and Christina Agapakis. Special thanks to the experts who wrote benchmark tasks and shaped project direction: Daniel Fulop, Matthew C. Watson, Adam J. Meyer, Sandrine Boissel, Jens H. Kuhn, Rishi Jain, Noah D. Taylor, Helena Shomar.
 |
|
 |
|