
Human Verification of SpatialBench
Two rounds of independent expert attempts define a verified subset of 115 spatial biology tasks and expose ambiguity in benchmark specification and grading.

SpatialBench measures agent performance on realistic spatial biology analysis tasks. The benchmark has 159 evals that span 5 spatial technology types, focusing on practical, local analysis work rather than longer-horizon scientific tasks.
All SpatialBench grading is deterministic and answers are evaluated quantitatively against ground truths constructed from careful analysis. However, over time we found issues with some evals.
Problem Ambiguity
Some tasks might depend on specific analysis decisions not specified in the prompt. In these cases, missing or ambiguous task context makes it difficult to understand if incorrect answers are due to lack of capability or poor instructions.
Grading Threshold Sensitivity
Other tasks have numerical answers with tolerance thresholds that allow a range of valid analysis methods to pass. Sometimes these tolerances were inappropriately calibrated, e.g. set too narrow, rejecting valid analysis paths the domain expert did not consider when framing the problem.
Main Results
To gain confidence that SpatialBench tasks were adequately specified, we needed evidence that each expected answer could be reproduced by an independent expert attempt.
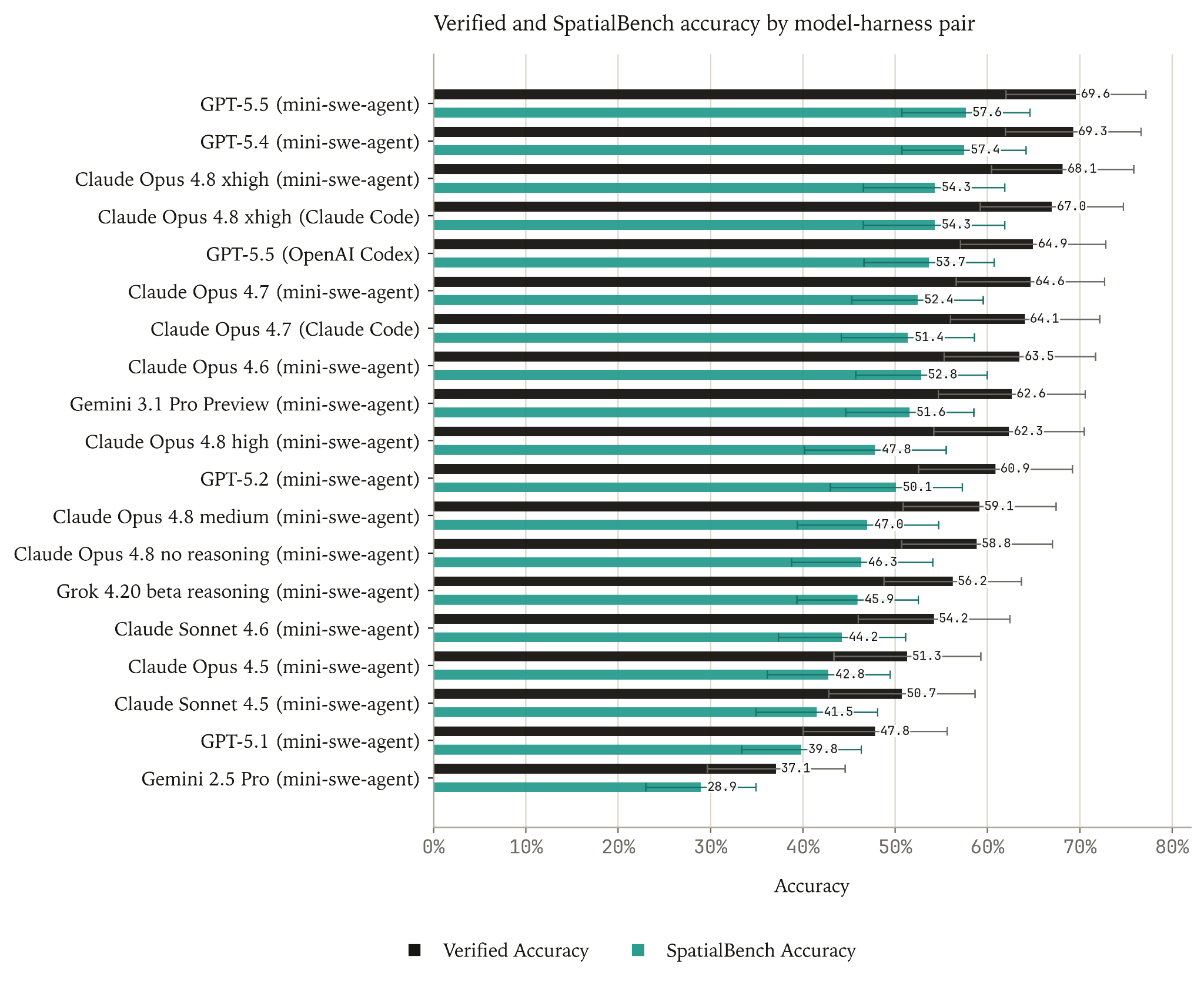
We constructed a human-verified subset of SpatialBench called SpatialBench Verified comprising 115 tasks. Each problem in SpatialBench Verified had at least one human expert independently reconstruct an answer that passes the task graders from just the task prompt and associated data.
We found the filtered subset preserved the relative ordering of model performance, but scores increased by 11.6 pp on average.
Example: Problem Ambiguity
This sa_02_microglia_oligo_inflammation_correlation task asked agents to partition a mixed gene list into microglial activation and oligodendrocyte inflammation signatures, score cells, find neighboring oligodendrocytes around each corpus callosum microglia using an “appropriate radius” and compute Spearman correlations at 90wk and 4wk.
With just the task and no solutions, a human reviewer returned:
{
"spearman_90wk": 0.14,
"spearman_4wk": 0.29,
"interpretation": 2
}The existing grader expected:
{
"spearman_90wk": 0.32,
"spearman_4wk": -0.17,
"interpretation": 2
}The reviewer actually agreed with the intended qualitative interpretation (‘2’): age-associated spatial coupling between activated microglia and inflamed oligodendrocytes. But their notes indicated the exact numerical values were not recoverable from the task as specified.
Why?
If you look at the original problem statement, open choices include:
how to split the mixed gene list into two signatures
whether shared inflammatory genes can appear in both signatures
how to normalize the low-depth targeted MERFISH panel
what radius counts as “neighboring”
whether to pool sections or control within section
whether the provided 50k subset has enough power for the 4wk correlation
A variety of defensible analysis methods were therefore possible given the task context, making it difficult to trust the eval result.
Example: Grading Threshold Sensitivity
This visium_bone_norm_within_niche_coexpression task asked agents to define bone-enriched Visium spots as the top quartile of COL1A1 (symbol for a collagen gene) counts, then compute the Pearson correlation between COL1A2 and SPARC within those spots. The desired biological conclusion was that COL1A2 and SPARC are strongly co-expressed in the bone compartment, consistent with a coordinated osteoblast matrix-secretion program.
Once again, without solutions and just the task, the human reviewer reproduced the intended biological conclusion and reported:
{
"n_bone_spots": 735,
"col1a2_sparc_corr": 0.8514,
"interpretation": 1
}The grader expected:
{
"n_bone_spots": 762,
"col1a2_sparc_corr": 0.62,
"interpretation": 1
}The reviewer’s notes actually found the correlation is highly normalization-dependent despite relatively stable biological interpretation. This is a clear example of a grader tolerance that was too narrow for the goal of the eval.
Methods
We conducted an initial round of review where 6 domain experts solved all 159 problems in SpatialBench at an average of 26 problems per expert. Human experts were given access to the task prompt and associated data, and were asked to produce an evaluation answer in the same format as the agent answer.
For each problem, experts were asked to share both the final answer they arrived at and a Python Jupyter notebook or R Markdown document using any bioinformatics libraries they thought appropriate. All answers were graded using the benchmark’s existing grader, with binary pass/fail scoring (all answer fields must be correct).
94/159 (59.1%) of problems passed the first round of review. Upon review of the failing cases we found that failures fell into several categories:
Poor solution effort
Valid effort but incorrect analysis
Unclear mismatch between human solution and ground truth
Ambiguous or weak eval specification
The first category of failures was mainly due to time constraints - over a week experts were asked to solve an average of 5-6 problems a day which proved to be unrealistic. To mitigate this, we carried out a second round of review.
For the second round of review we included all 65 problems that failed the first round as well as 10 passing problems to serve as a control. The passing problems were randomly sampled across the 5 different spatial technology types used in SpatialBench (2 per kit). Problems were assigned over a larger pool of 28 experts (3 problems per expert). Experts were given 2 days to produce solution artifacts for their assigned tasks.
Experts in the second round of review started afresh with just the task prompt and associated data. All problems were assigned to different experts between rounds.
Passing solutions were produced in Round 2 for 21/65 of the failing problems from Round 1. From the control set, passing solutions were produced for 8/10 problems in Round 2.
We took the union of problems that passed Round 1 review (94/159) and the 21 additional problems that passed Round 2 review, yielding 94 + 21 = 115 problems in SpatialBench Verified.
Supplements
Authors
Anirudh Narsipur, Deborah Hayoun, Ananya Gupta, Shivang Sharma, Benjamin Kesler, Zachary Hemminger, Sahar Nasr, Aashka Bhowmick, Sahiti Marella, Zhen Yang, Shon Kurian George, Soo Hee Lee, Qian Xu, Lior Schachaf, Harihara Muralidharan, David Calcagno, Birendra Saye, Asmita Lagwankar, Meenakshi Somadasan, Alex Urrutia, Ian Diks, Hannah Le, Kenny Workman