
Latch Data, a distributed file system for biotech teams
designing a consistent system, reasoning about correctness, writing a FUSE-based mount




Latch has built a distributed file system called Latch Data (LData) to provide safe and unified access to experimental data across biotech teams.
We briefly outline the design and properties of this system, emphasizing consistency and provenance, and describe some tricky scenarios that would break a naive implementation. We also show realistic ways that scientists would use it graphically and programmers would interact with it through a FUSE based mount or the command line.
Our emphasis is on interesting technical details in implementation and design, and intend for this post to be read by engineers.

Why we built this
Modern biotechs do different things with streams of experimental data and coordinate teams with diverse technical backgrounds. Bioinformaticians run workflows, computational biologists explore data in a notebook, software engineers live in the terminal, immunologists gate in FlowJo and molecular biologists analyze well plates in Excel. Data lives in AWS S3, Google Cloud buckets, Drive, Sharepoint, Box, Ignite and friends.
There is often no single source of truth and different teams put data in different places, from cloud buckets to local laptop hard drives, leading to fragmentation and confusion. Basic tasks like finding and sharing the correct copy of data, between or within teams, become difficult and research productivity stalls.
The design and properties of LData
LData is a distributed file system supporting file management and data operations on Latch across various computing environments. It provides a graphical user interface, a command-line interface, and can be mounted on Unix-based systems.
At its core, LData is a Postgres database which holds structural information (eg. parent-child relationships) and metadata about objects and “directories”. The data itself is hosted across different cloud providers, with support for user provided AWS S3 and GCP Buckets, along with our own managed and structurally optimized S3 bucket.
Consistency
The synchronization mechanism for these various storage locations is the most important piece of LData’s design. It uses a two-way sync to correspond the Postgres state with the backend storage provider, eg. an object moved in a bucket must propagate to LData and vice-versa. This process is handled by an asyncio-based service in Python, which processes updates from a queue of external and internal change events. The external change events are delivered via provider specific APIs, such as S3 bucket notifications, and we read and diff their state with ours.
When an object is created or updated in a storage backend, we get a notification which we parse into a database object which we have to create or update. On our side, nodes in our Postgres database are then marked with flags indicating their current state (e.g., removed, data_removed, copied_from, pending), with each service operation designed to transition a node from one state to another. State integrity is enforced by built-in features of Postgres like constraints and triggers, using transactions to wrap all logically dependent blocks.
The best way to understand the system working well is by walking through the removal of a subtree immediately followed by a file upload to the same key. In a single transaction, the subtree in our Postgres database is severed from its parent, the subtree is marked as removed, a witness edge is recorded in a provenance table, and the node id is queued into our work queue. Then an object is uploaded to the platform at a key in the subtree which clashes with one of the keys we are slated to delete. Let’s say this upload completes before we process the removal. When we process the removal, in a naive implementation, the removal would overwrite the new object upload. However, one of our supported states is removed but not data removed – aka someone removed a node on Latch but the corresponding file or subtree has yet to be deleted in the storage backend. We programmed the state transition from (removed, not data removed) to have possible outcome states of (removed, data removed) or (not removed, not data removed). When we go to process the nodes in the removed subtree, we can then compare the linearly increasing object version we have in our database for the removed node to that reflected in the s3 object. Based on the comparison, we know whether our local remove is stale and we can rollback to (not removed, not data removed), or whether we should proceed to delete the node. It should be noted that in this case we do not record data removed when we delete the node in the storage backend, and instead we immediately return. We wait for the storage backend to give us confirmation through their notification system, at which time we can be as sure as possible that the data is gone from the storage backend.
The system architecture emphasizes idempotency and statelessness, facilitating a reliable transformation of node state within the database. Idempotency is important as we have to assume notifications are entirely unreliable, can get delivered twice, or may never be delivered. There also may be configuration or other issues with the bucket notification, and assume at any point we may have to do a full diff of the tree in the storage backend and in LData, reconciling operations on both ends. Statelessness is important for more practical reasons – it allows us to scale services massively, not worry about interruptions or crashes, and significantly modularize and simplify each individual sync function.
These properties have made reasoning about the system much easier, allowing us to reasonably convince ourselves of correctness. For design correctness, this entailed sketching out the matrix of state transitions and ensuring each chain leads to a terminal state and that the terminal state corresponds with the intended initial state. For example, a user moving an object between buckets results in a removed object in the source bucket and a created object at the correct key in the target bucket, but much more importantly, that this operation is atomic (your data cannot fail to be transferred and be removed, as that would be very bad). We had a brief fourree into TLA+ to attempt formal verification of the system, but we realized that most of the benefits of modeling happened during writing the specs and clarifying them. After we had them thought through to some degree, we realized that the system was simple enough where we did not need TLA+. But it was still a huge benefit as it forced us to significantly simplify our system. For operational correctness, it is about running through every code path, ensuring each state’s input and output cross product is covered.
Provenance
With Latch either being the source or consumer of all filesystem events, provenance comes naturally allowing us to log every detail of user or system file interactions. This will allow for features such as restoring to a previous version of an object or getting a report of every action taken on a piece of data to be basically frontend features instead of hard engineering problems. Their support is baked into the system.
This capability is vital for auditing and compliance, and is a strong selling point as often tracking down the origin of a faulty edit is vital in verifying science.
Storage backends
Initially supporting only AWS S3, Latch Data has expanded to include compatibility with Google Cloud Storage and with our own managed S3 bucket, which has a more optimal structure for operations with large files. This flexibility allows users to bring their storage solutions (e.g., existing data buckets) into the Latch ecosystem. Furthermore, since LData only needs to have a representation of the up to date structure of the bucket to function, data does not need to be migrated onto the Latch platform.
Support for biological files
LData also facilitates biology specific augmentations in the form of processes. For example, when a file that meets certain criteria (such as type and size) is uploaded, Latch Data initiates data processing tasks. One example of this is fastqc on fastq files, which is dispatched to our workflow engine and eventually run on kubernetes. Since our workflow engine is already designed with LData as a first class input and output, this integration works well.
Using LData
Mounting
The most powerful way to interact with LData is mounting it as a filesystem on a Unix-like machine and interacting with the entire system with normal file operations, eg. terminal commands and arbitrary programs, as if it were backed by a local storage. To accomplish this, we’ve written a FUSE based filesystem that we automatically mount to each of our managed computers.
A bit about FUSE - motivation, history and application
FUSE is a framework for writing userspace filesystems. Before such frameworks emerged (and FUSE was not the first), developing filesystems required deep knowledge of the kernel.
FUSE instead allows you to define a collection of userspace functions for each of the standard file operations and pass them to the kernel when the filesystem is mounted. File operations are then routed through the kernel back to userspace where it runs whatever code you want. (The project documentation is particularly horrendous so we recommend reading this usenix paper to understand what's going on.)

There have been many interesting implementations of this framework. Some apply a standard transformation to each file operation, such as encryption or compression, and others provide a familiar file system interface to nontraditional storage backends, such as cloud buckets, Google Drive or even JSON objects.
LData FUSE
Generating GraphQL
We run a combination of GraphQL queries and subscriptions against a PostGraphile server sitting on top of our Postgres database to provide LData FUSE with the correct state of the filesystem for various operations.
Our implementation uses Python bindings for libfuse, so it was necessary to generate Python types from the GraphQL schema.
It was also desirable to generate asyncio coroutines from the necessary GraphQL operations (queries and subscriptions), that inject eg. websocket connection boilerplate and tracing, and can be used as library code within the FUSE implementation. These coroutines can be re-generated when the schema or GraphQL operations change.
For example, consider this subscription that provides information about LData nodes.
subscription LatchData($workspaceId: String!) {
consoleLdataNode(workspaceId: $workspaceId) {
table
rowIds
}
}We generate the following coroutine.
query_str_latch_data_subscription = "subscription LatchData($workspaceId:String!){consoleLdataNode(workspaceId:$workspaceId){table rowIds}}"
@trace_function_with_span(tracer)
async def subscribe_latch_data_subscription(
span: Span,
ctx: GqlWebSocketContext,
*,
callback: Callable[...],
operation_id: str,
variables: LatchDataSubscriptionVariables
):
span.set_attributes({"operation_id": operation_id, ...})
return await ctx.subscribe(...)Where we can poll it in the event loop.
await qlib.subscribe_latch_data_subscription(
self.ws_ctx,
operation_id="node_subscription",
callback=self.handle_latch_data_notification,
variables={"workspaceId": basic_info["accountInfoCurrent"]["id"]},
)In the simplest case, these subscriptions update our file system tree so that commands will show the correct set of files, even if a scientist was dragging files in and out of a folder on the graphical interface moments ago.
Improving performance with chunked file downloads
In our initial implementation, operations on files were blocked until the entire file downloaded, so that even reading the first few bytes of a file could take minutes if it was sufficiently large. Obviously this is not great.
If we instead download the file in smaller chunks and keep track of which ones have arrived, we can improve performance for reads that only need some of these chunks. To do this, the first open call dispatches many async download jobs for each chunk. Subsequent `read` calls wait until they have the chunks that they need.
We keep track of downloaded chunks using a global bitmap that has a bit for each chunk, a “0” if the chunk is not there and a “1” if the chunk is downloaded. A `read` is safe to proceed if it the chunks that it is asking for are downloaded. We can accomplish this using bit operations:
end = ceil(min(size + offset, self.content_size) / self.part_size)
start = ceil(offset / self.part_size)
mask = (1 << (end - start))
mask -= 1
mask = mask << start
# The final bit mask has 1s in [end, start] and 0s elsewhereWhere the check happens each time a download finishes, with each download job associated with a condition variable (to avoid thundering herd with an uncapped number of notifies) that tells the read to check if it the correct bits are there.
with self.part_finished_in_bin_cvs[i % self.cv_bins]:
self.bitmap |= 1 << i
self.part_finished_in_bin_cvs[i % self.cv_bins].notify_all()We are still exploring this approach, but it shows significant speedups when accessing small pieces of a file.
CLI
Following suit with the major cloud providers, we figured using the command line to move data around is often the easiest way to accomplish analysis tasks. We’ve implemented all the commands one would expect to move, view or otherwise manipulate objects in LData from the terminal.

Graphical Interface
One of the greatest utilities of LData is its ability to bridge the gap between the wet lab and dry lab.
Scientists can view and move data around graphically.
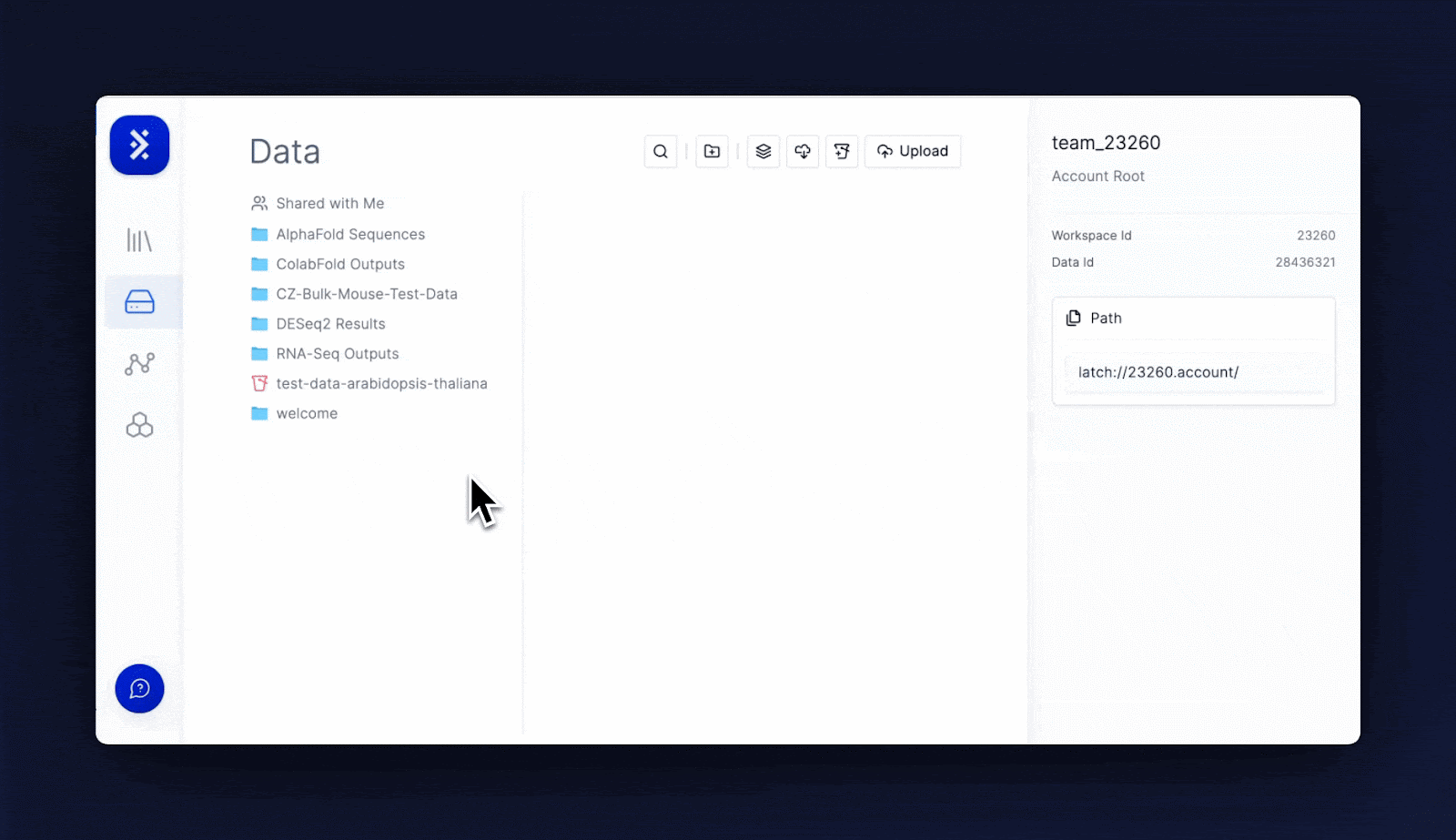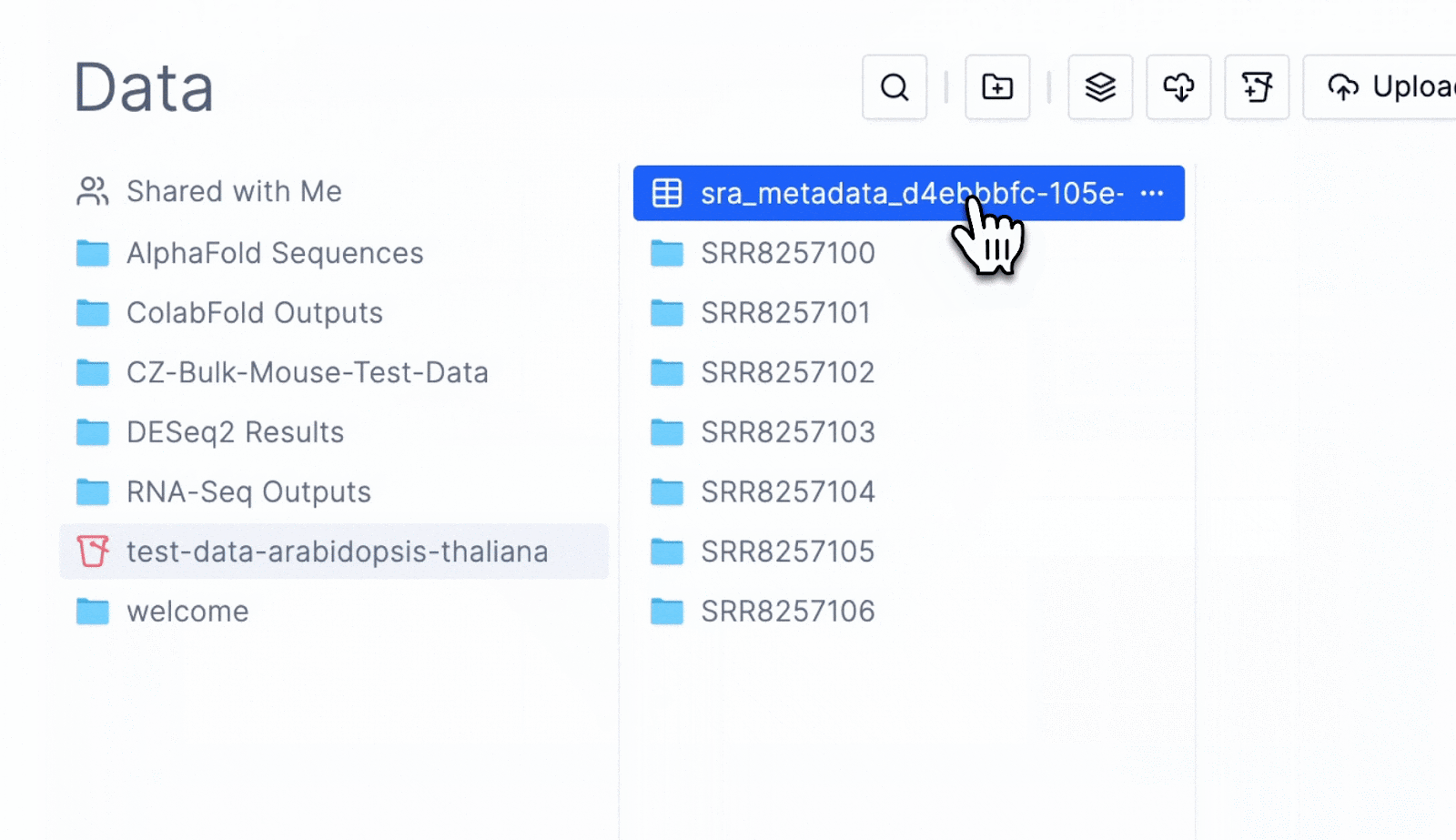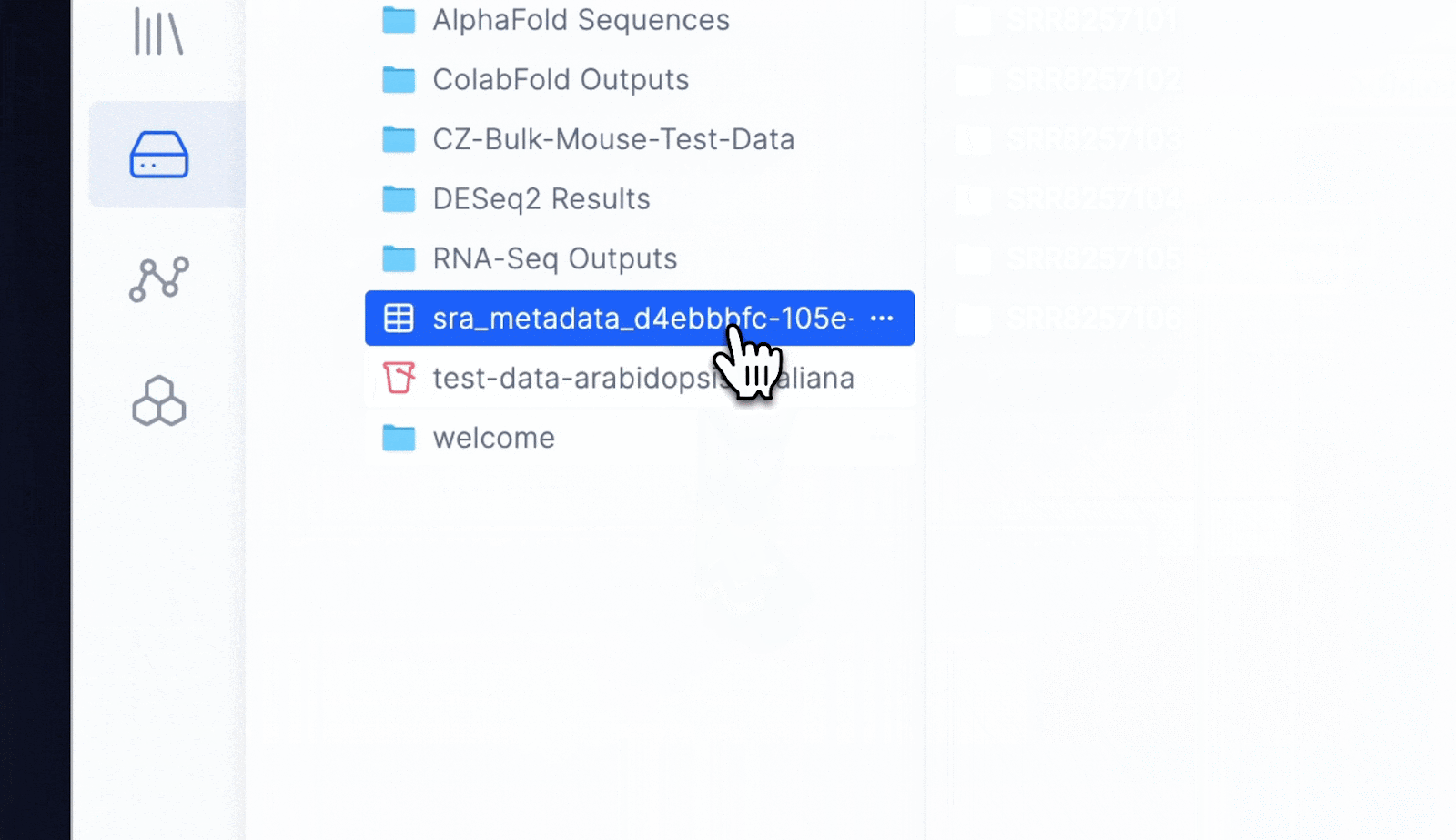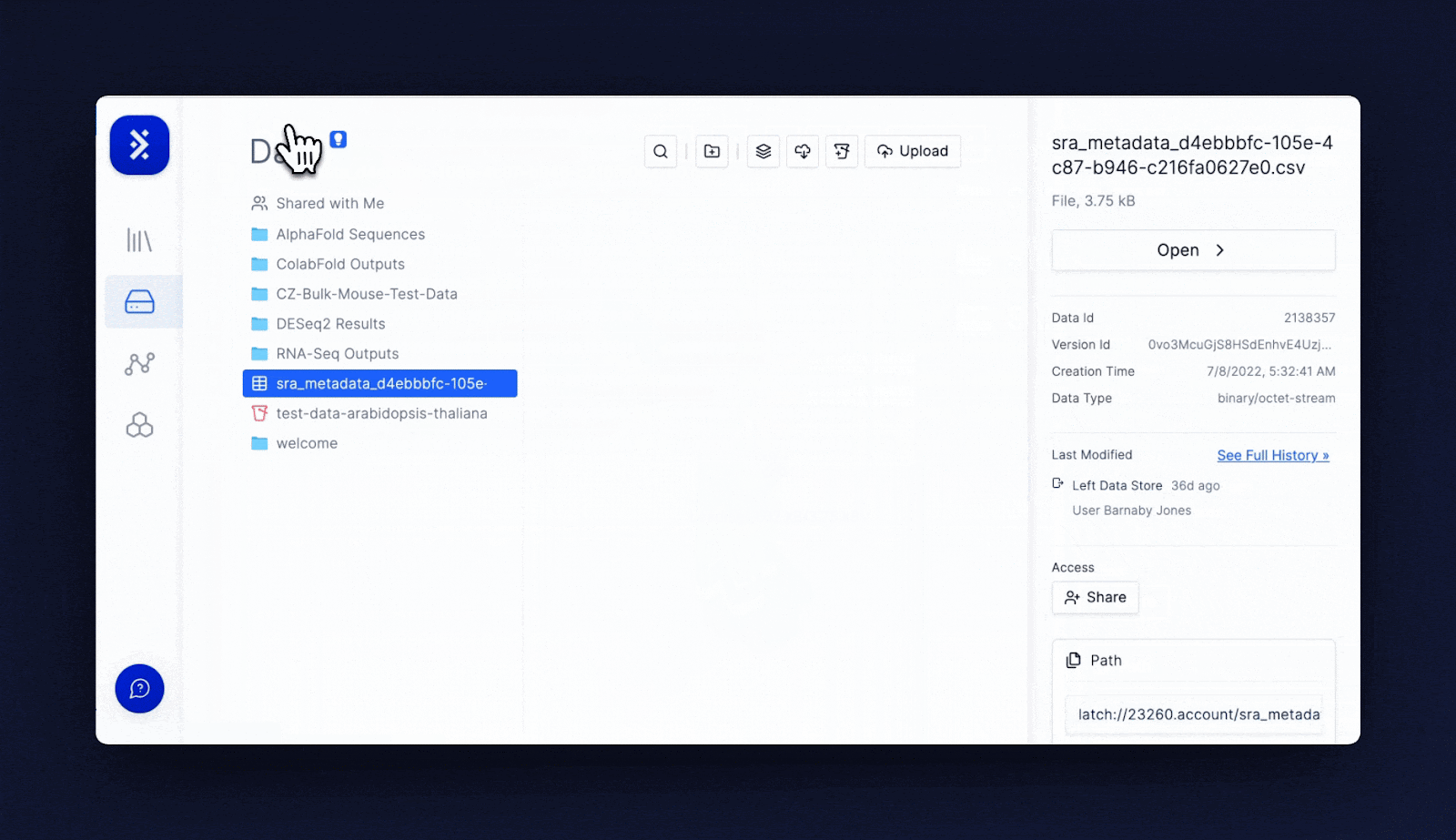
They can click into individual files and inspect genomes, sequencing files or simple CSVs/Excel/text files.

Want to build stuff like this?
At Latch, we enjoy working on problems at the intersection of systems engineering and biological data analysis. Please reach out to kenny@latch.bio if you want to learn more about our team.
—
Thanks to Nathan Manske and Hannah Le for the graphics and videos.
 | A guest post by
|
 |
|