
Latch Registry: An integrated database for multi-omics
A unified multi-omics database for the wet and dry lab

Managing and collaborating on multi-omics data becomes increasingly challenging as a biotech organization scales. Throughout the entire R&D life cycle, scientists must track samples and project metadata across Excel spreadsheets and internal LIMs, while computational teams must link raw data and reports to those samples. With no database linking wet lab <> dry lab, current solutions are siloed between AWS, Excel, Benchling, and Powerpoint, leading to a lack of traceability, visibility and slower decision making in R&D.
Let’s take a simple bulk RNA-seq example:
Different lentiviral libraries with gene knock-ins are prepared.
Lentiviral libraries (with gene knock-ins) are introduced into mice models
Samples from different organs are extracted.
Samples are processed and sent for sequencing.
The sequencing provider returns the BCL or FastQ files via S3 or their own cloud.
A bulk RNA-seq pipeline is run on AWS to yield gene expression counts.
Count files are deposited to an S3 bucket.

Every step of the above data generation cycle involves tracking multiple pieces of information, such as lentiviral concentration, tissue types, and more. The issue arises when it becomes necessary to combine metadata in the wet lab upstream with bioinformatics results downstream:
What is the relationship between lentiviral injection dose and the expression of specific genes or pathways?
Is there a relationship between lentiviral injection dose and the sequencing quality metrics (e.g., mapping rate, duplicate rate, base quality scores)?
Do different tissues exhibit distinct gene expression signatures, and if so, can we identify tissue-specific markers?
Bioinformaticians and scientists now face the arduous task of sifting through extensive Excel spreadsheets to pinpoint the appropriate metadata, a process that involves days of tedious back-and-forth. At the same time, team executives find it nearly impossible to gain a clear, real-time picture of high-throughput experiments and their results. Instead of spending valuable time and resources on differentiating sciences, teams are bogged down in a labyrinth of files and metadata.
Existing Solutions Fall Short
To solve the multi omics metadata management problems, computational and data teams have tried a few solutions:
Setting up SQL databases or Google BigQuery to track URL paths to files in cloud storage with additional column values
Using a spreadsheet, like Notion or Google Sheet, to track wet lab metadata.
These solutions break down due to:
Lack of dynamic linking: Once the file object gets moved or deleted, your static path in the Excel spreadsheet or SQL database immediately needs to be updated.
Lack of metadata validation: Without constraints and data standardization on input fields, it is not uncommon for scientists to make typos or fill out a wrong piece of information on an Excel sheet. The invalidated data can cause failures in bioinformatics downstream, resulting in experimental delays.
Lack of data traceability and linkage: When data is stored across different sheets, it’s hard to establish the links and relationships between other sheets. This makes navigating and searching for the right piece of information difficult.
Lack of programmatic queryability: Computational teams need APIs to filter and query for insights. For example, all patients with x tissue type and y expression profile.
Lack of accessibility: Data stored in BigQuery or SQL databases are inaccessible to scientists and executives, hindering visibility into progress across different R&D projects
Challenges integrating tables into workflows: Bioinformatics workflows often need access to sample sheets with correct paths to files and validated metadata as inputs. Bioinformaticians often spend hours manually cleaning Excel sheets, before they can be in a format that the workflow can ingest.
Latch Registry: An Integrated Database for Multi-omics Data
Today, we are introducing Latch Registry: An integrated database for multi-omics.
Instead of managing multiple databases, put all the data you generate together in one harmonious database: Latch Registry
Registry allows you to track everything, linking data from your patients → tissues → samples → specimens → slides → assays → raw data objects → analysis objects in a single place. This makes it easy to access, explore, and query data for insights.
Registry is built to supercharge team collaboration:
Scientists can link sequencing files to contextual metadata collected in a lab through a familiar spreadsheet interface.
Bioinformaticians can easily bring samples and validated metadata from Registry into bioinformatics workflows on Latch.
Computational biologists can query all metadata in Registry programmatically via a Python or R API, whether in a notebook environment or other downstream analyses tools.
Executives can easily see overviews of all the analyses.
Let’s see Registry in action! Here, our product manager Hannah Le will walk you through how you fill out a Registry table with sample conditions, associate each sample with AWS S3 files, use Registry samples as input to the bulk RNA-seq workflow on Latch, and have the workflow write results back to Registry:
Built for Teams
Familiar Spreadsheet Interface for Scientists
Scientists don’t have to learn a new software system. Latch Registry comes with a familiar spreadsheet interface that is easy to fill out. Scientists can also directly import from existing Excel Sheets and CSV to more rapidly enter data.

Python & R API for Developers
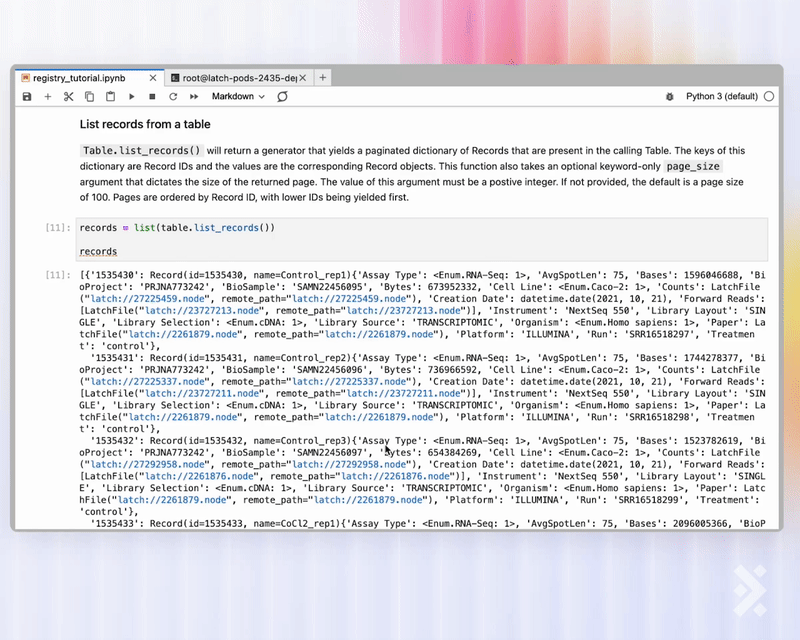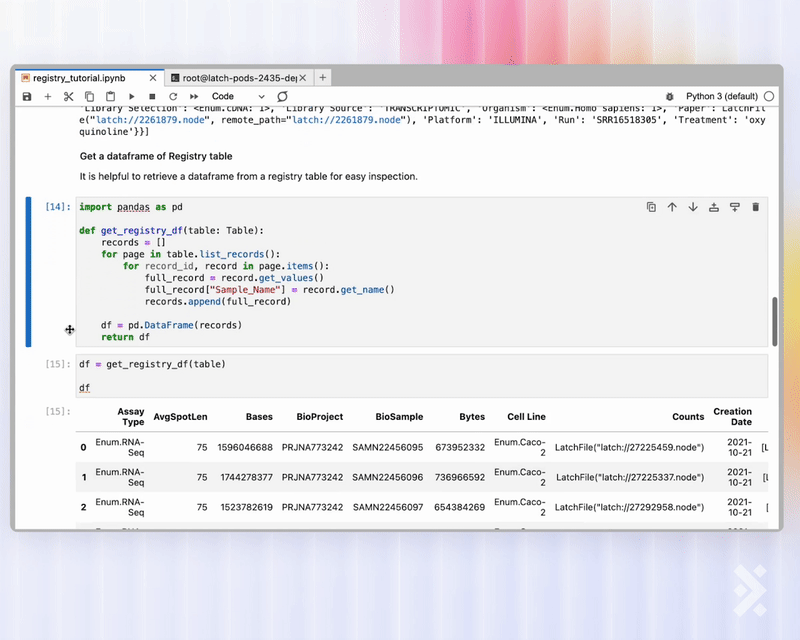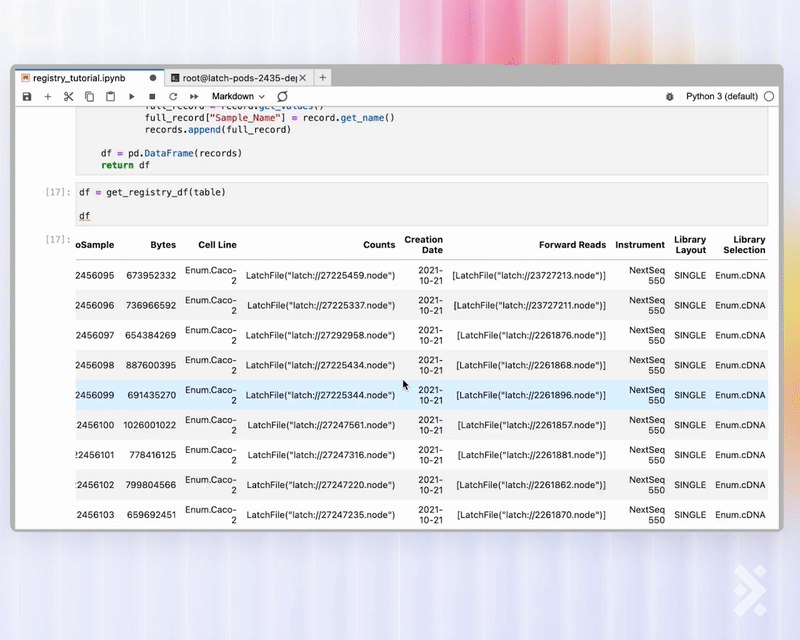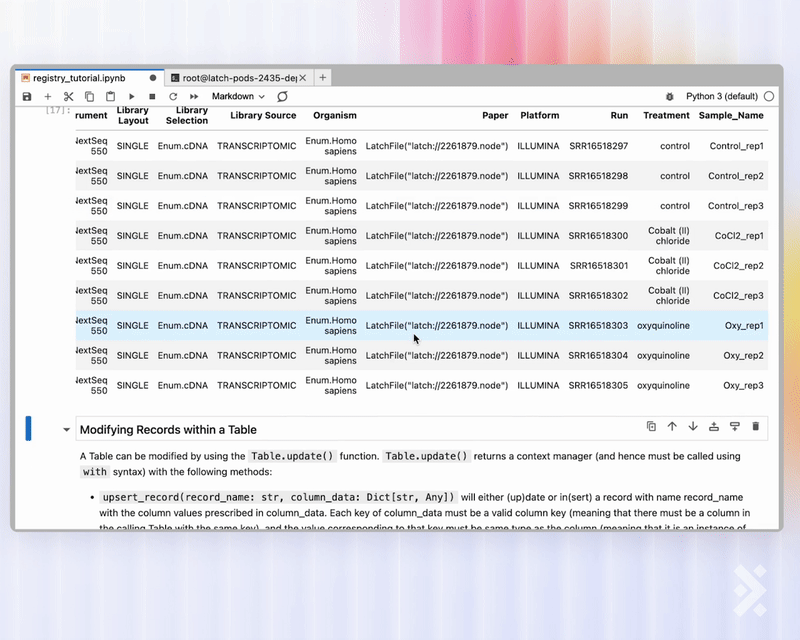
Registry is developer-friendly. Quickly retrieve any Registry tables using the Python or R API.

Enable more Complex Relationships between Tables via Linking
As biological data is centralized in Latch Registry, records across tables share relationships or dependencies. Linked records allow users to define connections between entries across different tables, enhancing data analysis and uncovering new insights that might have otherwise been challenging to discover without linked records.

Integrated with the Latch Ecosystem
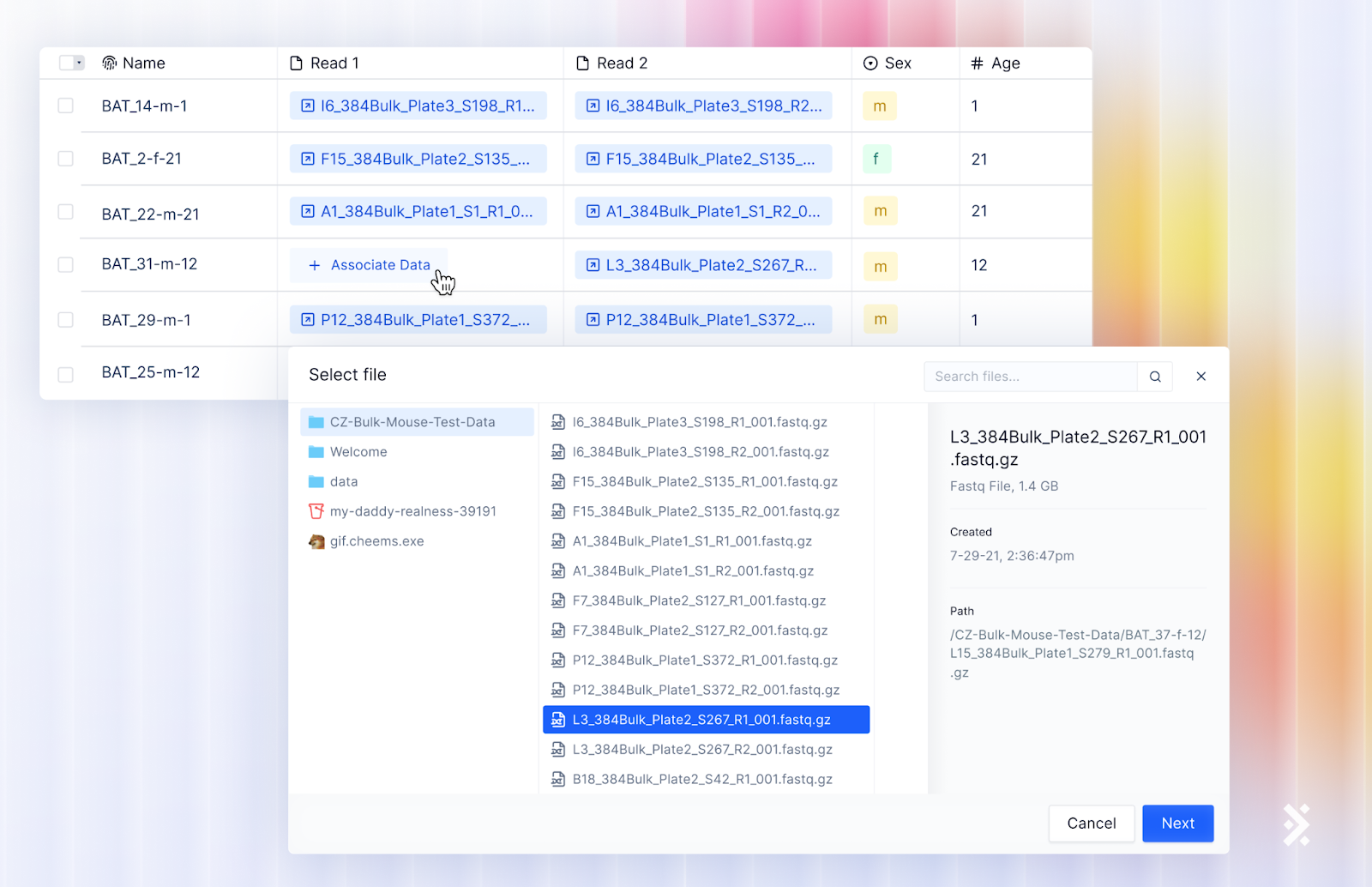
One-click to associate metadata with files on Latch Data
Latch Data offers a user-centric data storage system, similar to Finder on OSX, allowing folder creation and flexible data organization.
With just a few clicks, scientists and bioinformaticians can effortlessly link a file in Latch Data to extensive metadata and column values stored within the Registry.
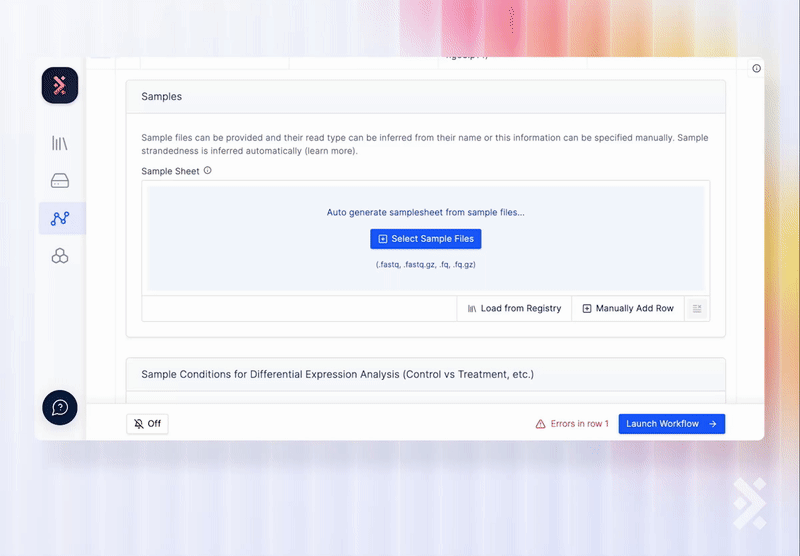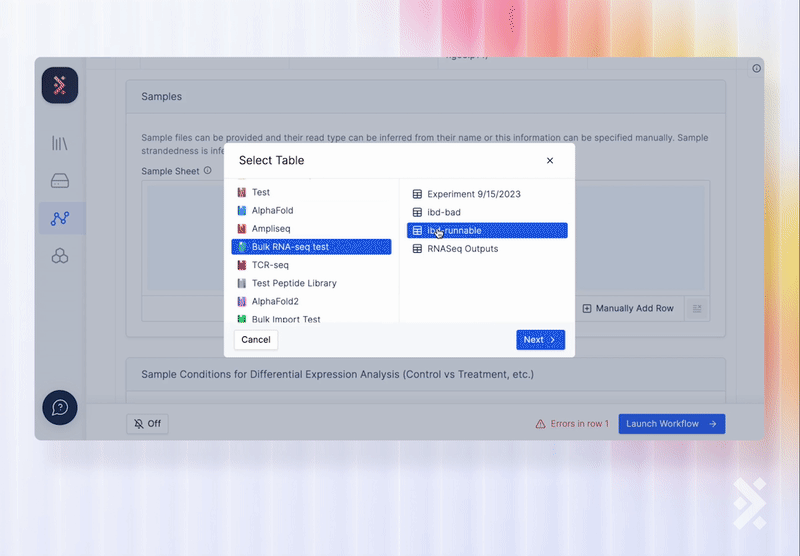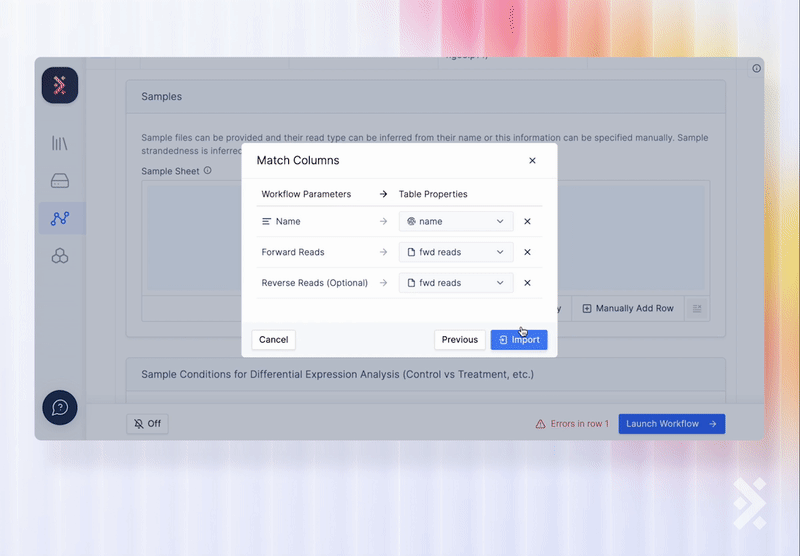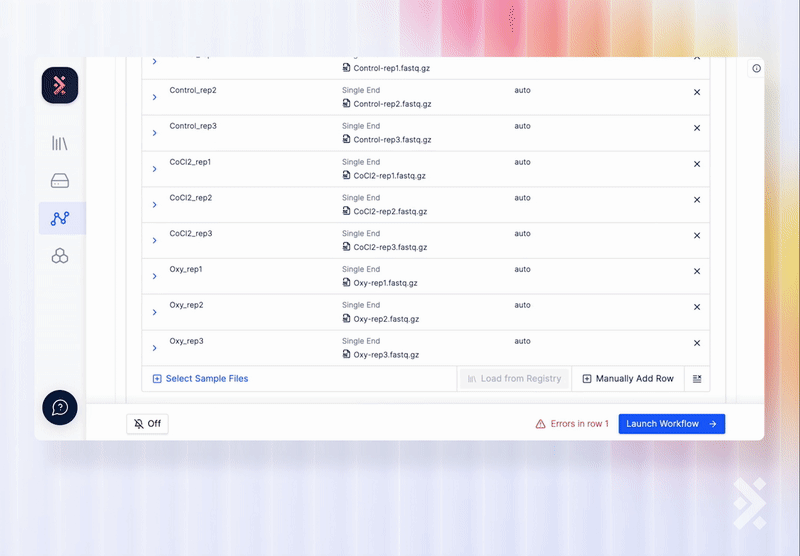
Integrates with Latch Workflows
On the Latch Workflow interface, scientists can easily select samples from Registry as input to the workflow.
A developer can also use the Registry API to add a workflow task which writes back to a Registry table when the workflow finishes executing.
Run queries from Latch Pods
Latch Pods are scalable and flexible compute environments with RStudio & Jupyter Labs pre-installed.
Scientists and bioinformaticians can easily spin up a GPU pod and use the Registry API to retrieve a panda dataframe of any table for further processing.
Connect your Internal LIMS
Rather than replacing ELN and LIMS, Registry links with them, completing an integrated ecosystem for large biological data. In the near future, we will be releasing functionalities to make it easy for teams to import from existing data sources, whether that’s internal database, Benchling, or public databases.
Getting Started with Registry
Every new account comes with an example Registry table and ability to create unlimited tables.
To get started, visit Latch Registry at https://console.latch.bio/registry
Learn more about Registry with our resources below:
User Guide: https://wiki.latch.bio/wiki/registry/what-is-a-registry
Developer Docs: https://docs.latch.bio/registry/overview.html