
Verifiable Benchmarking of Long-Horizon Spatial Biology
Evaluating whether AI agents can recover complex scientific conclusions from raw spatial biology data

Introducing SpatialBench-Long, a benchmark for long-horizon spatial biology. Agents must recover biological claims from raw data and realistic experimental context without prescribed methods.
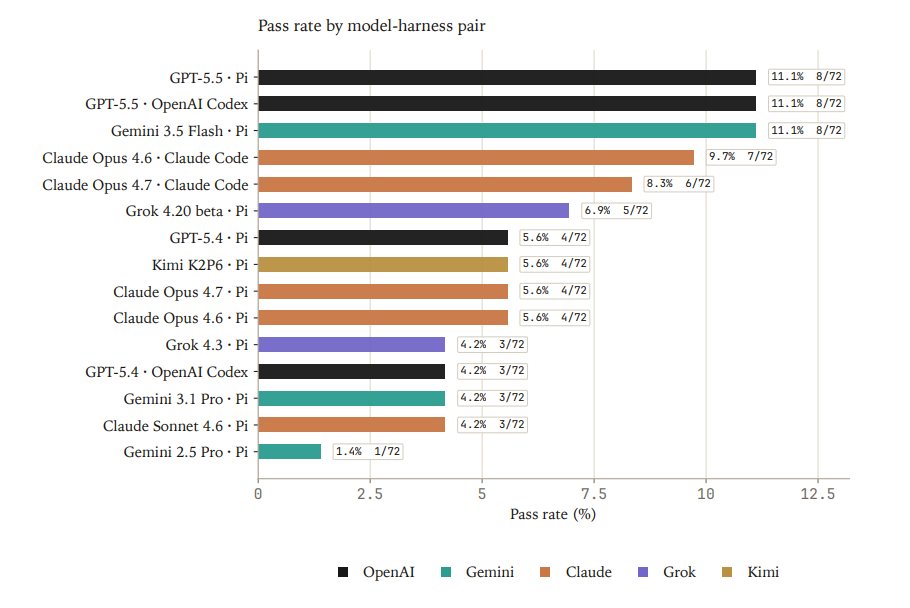
24 evaluations span primary tumors, organoids, xenograft models, lineage-tracing systems, and aging/intervention biology. The best agents score 11.1%.
Read the manuscript.
Interact with the leaderboard.
Benchmark Construction
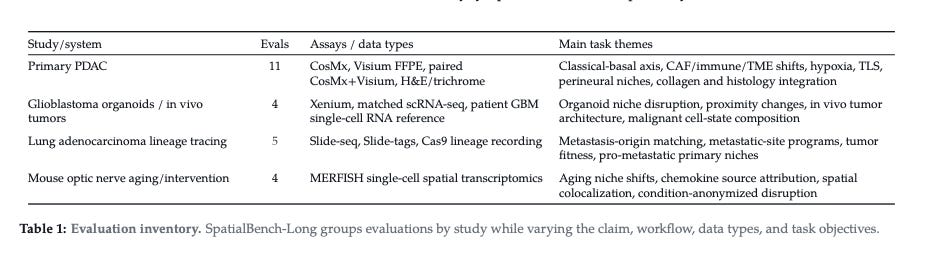
Evaluations mix the assay types scientists use in practice.
A single task may depend on spatial transcriptomics, histology, single-cell references, and lineage-recording data. Solving them requires cross-assay reasoning, experimental-design awareness, and command of spatial workflows like tissue segmentation, niche analysis, and spatial differential expression.
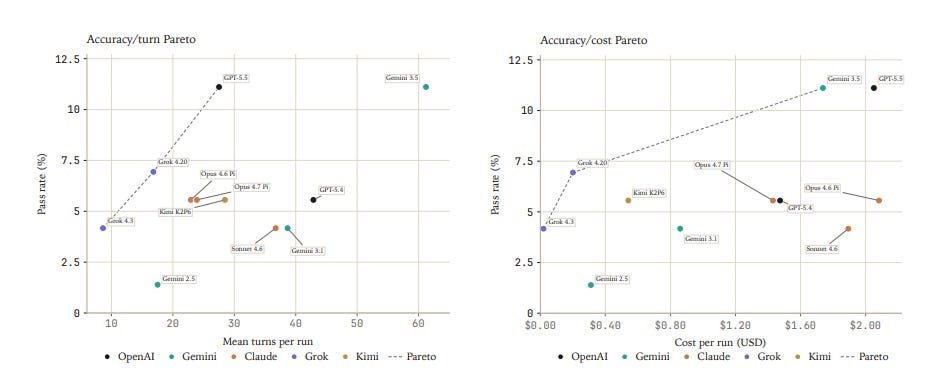
This tests the transition from running data analysis to doing science.
Constructing ground truth in science
Deriving ground truth is very hard in long-horizon biology benchmarks. The same data can support multiple valid conclusions, and some published claims do not reproduce cleanly under unbiased reanalysis.

Candidate tasks are hardened through independent reproduction, randomized expert review, and trajectories from multiple model families.
Pairing deterministic grading with diagnostic rubrics
Grading uses deterministic functions over structured final answers. We grade recovery of scientific conclusions expressed through controlled biological vocabularies instead of numbers from individual statistical operations.
Results
Across 15 model-harness pairs and 1,080 trajectories, Gemini 3.5 Flash / Pi, GPT-5.5 / Pi, and GPT-5.5 / OpenAI Codex each passed 8/72 attempts (11.11%), with Claude Opus 4.6 / Claude Code close behind at 7/72 attempts (9.72%).
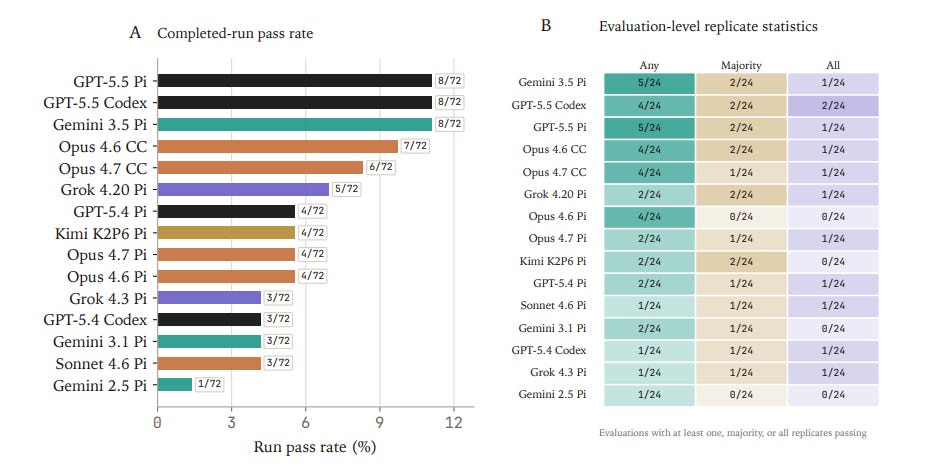
Judge rubrics over analysis ‘chokepoints’ provide interpretive tools
However, final-answer grading provides sparse diagnostic signal for long-horizon tasks. Chokepoint rubrics - analysis decisions expected to remain stable across plausible solution paths - are graded by judges as a companion diagnostic.
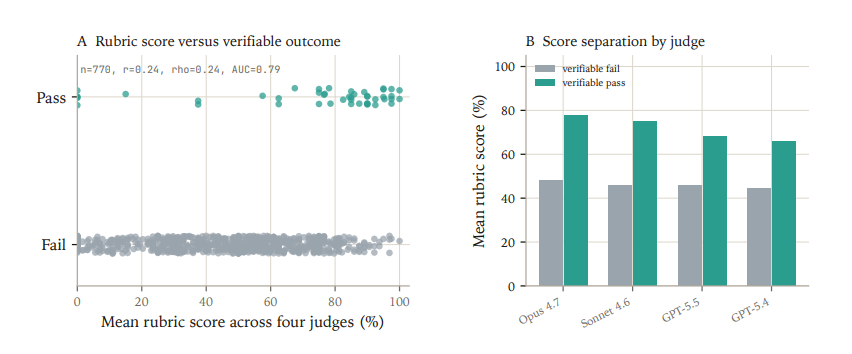
But rubric judging is probably not a replacement for verifiable grading
We were interested in exploring the utility of rubric grading for intermediate reward and asked if denser signal was partially aligned with endpoint quality. We conclude rubric scores are promising auxiliary tools, not substitutes for verifiable endpoint grading.
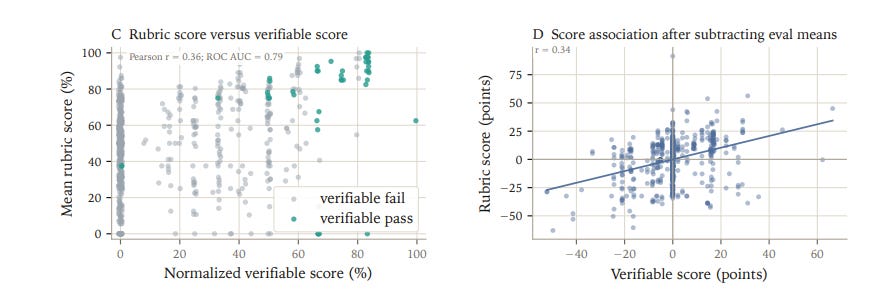
Rubric judging is reasonably stable over judge and agent model variation
We also stratified rubric scores by the source agent model whose trajectory was being judged to see if rubric patterns are consistent across judges. All four judges preserved the same broad ordering with some variability.
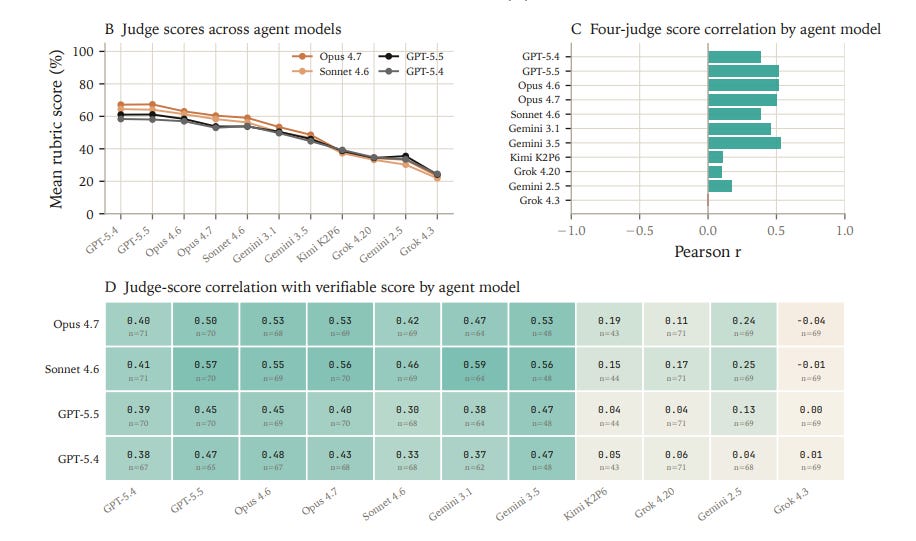
Actually looking at your trajectories will continue to be important
Pairing manual trajectory review with rubric and verifiable scores provides more tools to interpret model failures.
In practice, manual trajectory inspection is a first-class tool to understand this data. Eval authors maintain reproduction notes to provide a record for future benchmark updates, especially as stronger models may solve tasks through unanticipated but valid analysis paths that challenge current grading assumptions.
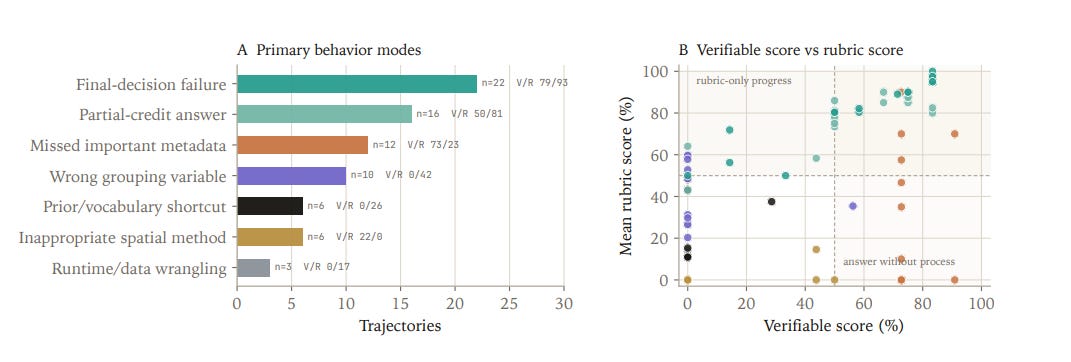
There is a path to agents that behave a lot like scientists
Results suggest compounding local analysis errors prevent reliable long-horizon scientific reasoning.
Before models can reliably reason about disease mechanisms, drug response, or other deep results in biology, they must become procedurally competent in local steps.
But the few task completions we observed were very impressive. It seems there is a realistic path to agents thinking and behaving a lot like scientists do.
Read the manuscript
Interact with the leaderboard