
A Primer on NGS Technologies and Their Specs (2025)
A technical overview of 10 companies, 37 sequencing instruments, and their specs


All roads lead to a sequencing machine.
The past decade has witnessed many advancements in the scale and type of modality we can measure. Take the example of Takara Trekker, a clever technique to tag each nucleus within its native tissue environment with unique spatial barcodes using UV light. Or Parse Biosciences’ Penta kit, which uses a split-and-pool approach to barcode one to five million cells without the need to use microfluidics instruments for physical single-cell isolation. Even large-scale proteomics workflows, such as those from Olink or CITE-seq, now rely on antibodies conjugated to unique DNA sequences to convert protein abundance into a sequencing-compatible readout.
Whether you're measuring gene expression, chromatin state, protein abundance via DNA tags, or spatial context, the final step in these workflows is almost always the same: sequencing.
Originally built to read the human genome, modern sequencers have become general-purpose molecular readout devices—a universal endpoint for biology.

As of June 2025, the market features 37 sequencing instruments. To help navigate this landscape, we’ve mapped out the 10 key companies building these platforms, compared them across core technical attributes, and published a database to make the data easier to explore and debate.
You can access the database here, and if you see an error or want to contribute, leave a comment. This is meant to be a living and collaborative resource for the community.
In this article, we will explore:
From Sanger to Today: The History of Sequencing Technologies
Key Players in 2025: A Quick Rundown of Their Latest Chemistries
The U.S. seems to be trailing behind Chinese manufacturers in terms of throughput and speed.
Scientists need to navigate the cost per genome vs instrument price paradox.
Is Cost per GB all that matters? Beware of hidden infrastructure costs.
Multi-omics Support: Are sequencing machines evolving into something more?
We hope this will become a comprehensive resource for researchers as they navigate the NGS landscape in 2025.
From Sanger to Today: The History of Sequencing Technologies

1977 - 2005: The Foundation Years
The story of DNA sequencing begins in 1977 with Fred Sanger's chain-termination method, a breakthrough that first made reading the language of life possible. Sanger's initial triumph was modest by today's standards, decoding the 5,000-base genome of bacteriophage φX174, but it represented humanity's first glimpse into the digital code underlying biology. This pioneering method relied on clever chemistry: DNA polymerase would incorporate modified nucleotides that terminated chain extension, creating fragments of different lengths that revealed the sequence through gel electrophoresis.
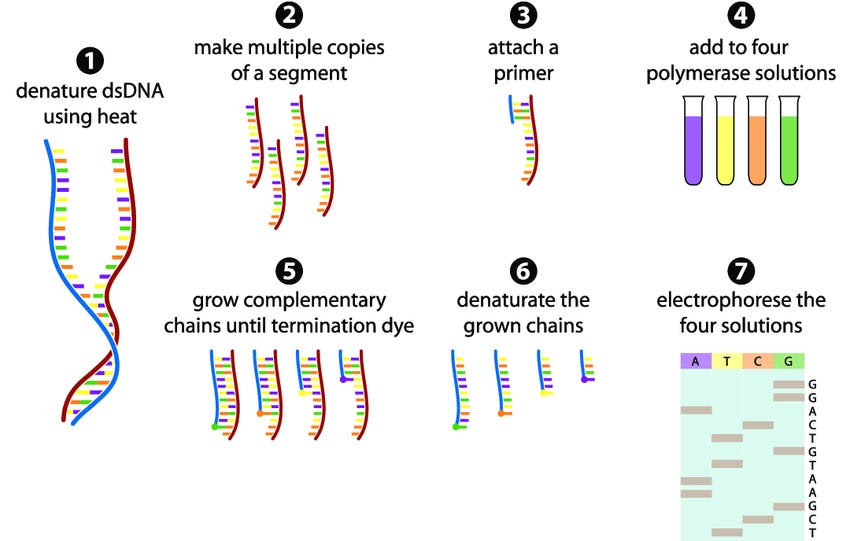
For nearly three decades, Sanger's approach dominated the field through incremental improvements. The 1980s and 1990s brought automation via capillary sequencers, replacing labor-intensive gel systems with continuous processing machines. Yet even automated systems remained fundamentally limited; they were accurate but painfully slow, requiring years and tens of millions of dollars to sequence a single human genome. The Human Genome Project, completed in 2003, represented this era's culmination: a heroic international effort that demonstrated both genomics' transformative potential and the desperate need for faster, cheaper technologies.
2005 - 2010: The NGS Revolution
The mid-2000s brought the advent of “next-generation sequencing” (NGS), characterized by massively parallel short reads. 454 Life Sciences introduced a pyrosequencing platform in 2005 (read lengths ~100s of bases), and in 2006-2007 Solexa/ Illumina launched its sequencing-by-synthesis (SBS) platform, followed by Applied Biosystems’ SOLiD. These second-generation sequencers could generate gigabases of data in days, massively reducing the cost per base (dropping from ~$10,000 per megabase to mere cents). Illumina’s SBS technology quickly came to dominate the market, due to its accuracy and throughput. Over the past decade, Illumina has at times held ~80% of the sequencing market share.
2010s: The Rise of Long Reads (Third-Generation)
In the 2010s, third-generation sequencing technologies emerged, distinguished by the ability to sequence single molecules and produce much longer reads (thousands to tens of thousands of bases).
Pacific Biosciences pioneered this transition with their Single Molecule Real-Time (SMRT) sequencing platform in 2011. Their zero-mode waveguides created optical chambers where individual DNA polymerases could be observed incorporating fluorescent nucleotides. Oxford Nanopore Technologies took a different approach, threading DNA through protein nanopores and measuring electrical signal changes as bases passed through. When ONT's MinION launched mid-decade, it brought sequencing capabilities to a USB-stick-sized device.
These long-read platforms initially faced skepticism due to higher error rates, but the errors were random rather than systematic, making them correctable through coverage or consensus approaches. More importantly, long reads solved problems short reads couldn't address: de novo genome assembly of complex regions, large structural variant detection, and full-length isoform sequencing. As accuracy improved (PacBio's HiFi reads achieving over 99.9% accuracy, ONT's newer chemistries reaching ~99% single-read accuracy), long reads transitioned from specialized tools to mainstream platforms.
By the late 2010s, the cost of sequencing a human genome had fallen below $1,000, a milestone achieved well ahead of the trajectory of Moore’s Law.
2020s: Toward Multi-omic, Spatial, and Ultra-High-Throughput Sequencing.
We are now in a new phase defined by multi-omic compatibility, spatially-resolved sequencing, and ultra-high throughput machines. Sequencing is being integrated with other modalities: for example, Illumina and Singular Genomics are developing workflows to sequence not just genomes, but also spatial transcriptomics. Illumina also recently acquired SomaLogic, signalling its movement into the proteomics field.
Throughput has also exploded. Traditional “high-throughput” sequencers output on the order of a few terabases per run, but new instruments are extending this by an order of magnitude. Illumina’s latest NovaSeq X series, for instance, can output up to 16 terabases of data in a single run (26 billion reads per flow cell), and emerging players are pushing costs down further (more on this below). There is also a convergence of technologies: short-read companies are adding long-read or synthetic-long-read capabilities, long-read companies have launched short-read platforms, and entirely new chemistries are being introduced. All of this means researchers in mid-2025 face a rich but complex menu of sequencing options.
Key Players in 2025: A Quick Rundown of Their Latest Chemistries

Oxford Nanopore: ONT’s Q30 Duplex Kit14 (launched 2024)
Oxford Nanopore Technologies (ONT) sequences DNA using biological nanopores: tiny protein channels embedded in a membrane that detect DNA molecules as they pass through. As a single-stranded DNA molecule moves through the pore, it causes disruptions in ionic current. These changes are measured and interpreted by machine learning models to identify the underlying nucleotide sequence in real time.

Traditionally, ONT relied on simplex sequencing, where only one strand of a DNA molecule is read. While this allows for extremely long reads, often tens of kilobases or more, simplex reads suffer from several challenges. The signal measured by the pore reflects a short k-mer (typically 5 or 6 bases), making it difficult to resolve individual bases when homopolymers or repetitive regions are present. Because only one strand is read, there is no independent validation of each base, so errors-especially insertions and deletions-tend to persist.
As a result, simplex reads historically achieved modal accuracies of only Q15 to Q18, or about 97 to 98 percent accuracy.
The introduction of Q20+ Kit14 brought ONT’s first broadly available duplex sequencing chemistry. In duplex mode, both strands of a double-stranded DNA molecule are sequenced in succession using a specially designed hairpin adapter. The basecaller then aligns the two reads and compares them to correct random errors and resolve ambiguous regions. Because the errors in each strand are largely uncorrelated, this reconciliation process significantly improves confidence in each base. Simplex reads now achieve around Q20 (~99%) accuracy, while duplex reads regularly exceed Q30 (>99.9%), rivaling the performance of short-read platforms in base-level precision.
Practically speaking, this means that ONT with Q20+ Kit14 can now be used for workflows previously out of reach for nanopore due to accuracy concerns, such as low-frequency variant detection, cfDNA sequencing, or methylation-aware diagnostics, while still enabling applications Illumina cannot touch, like ultra-long read assemblies, haplotype phasing, or native DNA/RNA modification analysis.
Pacific Biosciences: HiFi Chemistry on Revio (launched 2023)
Pacific Biosciences (PacBio) developed a sequencing method called single-molecule real-time (SMRT) sequencing, which watches DNA being copied in real time, one molecule at a time. In this system, a single DNA polymerase enzyme is anchored inside a tiny well called a zero-mode waveguide (ZMW). These wells are designed so that only the very bottom, where the enzyme is working, is illuminated. As the polymerase adds each nucleotide, which carries a unique fluorescent tag, the system detects a quick flash of light and records which base was incorporated.

This technology allows PacBio to read very long stretches of DNA without needing to break them up into short fragments, but early versions of SMRT sequencing had a major drawback of low accuracy.
Because each molecule was only read once, errors from things like fluorescence misreads, dye noise, or enzyme slippage made the data noisy. Single-pass reads often had error rates around 10-15%, especially in homopolymer regions or sequences with complex structure.
To solve the accuracy problem in its original SMRT sequencing, PacBio developed HiFi reads (short for High-Fidelity reads), which combine the length advantages of long-read sequencing with the accuracy of short-read platforms.

Instead of reading a DNA molecule once, PacBio circularizes each DNA fragment using special adapters, forming a loop called a SMRTbell template. The DNA polymerase then continuously reads around the circular molecule, passing over the same insert multiple times, usually 10 to 20 passes. Each pass produces a slightly different version of the sequence due to random errors. By averaging these multiple observations, PacBio’s algorithm generates a circular consensus sequence (CCS) that is highly accurate.
This technique drastically improves read quality. HiFi reads typically range from 10 to 25 kilobases in length, and because they’re built from multiple subreads, they reach Q30 to Q40 accuracy (99.9-99.99%).

Starting at a modest $600M in revenue in 2023, long-read sequencing is projected to reach $1.34B in 2026, likely due to increased market trust and accuracy.
Pacific Biosciences: SPRQ Chemistry (launched late 2024)
Building on the success of HiFi sequencing, PacBio took a bet on their first multi-omics chemistry: SPRQ (pronounced “spark”), designed to extract both DNA sequence and regulatory information from the same molecule.
Unlike bisulfite or enzymatic methods that chemically modify or fragment DNA, SPRQ preserves long, native DNA molecules. A transposase enzyme is used to preferentially insert special adapters into open (accessible) regions of the genome. These adapters include 6-methyladenine (6mA) marks. Open chromatin tends to be more accessible to the enzyme, so this step selectively “labels” active regulatory regions.
As with standard HiFi sequencing, these DNA fragments are circularized into SMRTbell templates, which allows the polymerase to read the same molecule multiple times for high-fidelity consensus sequencing. PacBio’s polymerase begins copying the circular DNA in real time.
As it passes through modified regions (like 6mA or naturally occurring 5mC), the speed of base incorporation changes slightly. These kinetic "pauses" or slowdowns are subtle but measurable. The sequencing software detects these polymerase slowdowns and matches them to specific base positions. It then combines: base sequence from HiFi reads (Q30-Q40), 6mA tagging patterns (open chromatin), and methylation signals like 5mC (native epigenetics). In just one sequencing run, SPQR provides high-accuracy DNA sequence, maps of chromatin accessibility, and detection of base modifications like 5mC and 6mA.
Element Biosciences: Cloudbreak UltraQ (launched 2024)
Element’s AVITI system uses sequencing-by-synthesis (SBS), but with a unique chemistry built around rolling circle amplification (RCA). Instead of reading a single DNA strand, AVITI circularizes DNA fragments and amplifies them into dense clusters called polonies, thousands of identical copies of the same DNA molecule in one spot. As the sequencer adds fluorescently labeled bases one at a time, it captures images and averages the signal across all the identical copies in the cluster. This built-in redundancy helps reduce random noise and improves overall base-calling accuracy.
In 2024, Element introduced Cloudbreak UltraQ, a high-accuracy upgrade to its standard chemistry. UltraQ builds on the same core principles but increases the number of observations per base and improves the enzymes and dyes used during synthesis. This results in sharper signals and cleaner base incorporation, which the AVITI’s software can use for even more precise error correction. With UltraQ, the system reaches Q50+ accuracy (just one error in 100,000 bases!)

Illumina: XBS-LEAP (launched 2023)
Illumina’s newest sequencing chemistry (as of 2023-2025) is XLEAP-SBS™, which was
introduced with the NovaSeq X series instruments. XLEAP-SBS (previously code-named “Chemistry X”) is an overhauled SBS chemistry engineered for faster cycle times and higher accuracy. Not a lot of technical details are available online on how the chemistry actually works, but Illumina claims the following improvements: a new thermostable polymerase, optimized fluorescent terminator nucleotides, and upgraded clustering chemistry on patterned flow cells . The result is roughly 2× faster incorporation speed per cycle and up to 3× greater basecalling accuracy. In fact, NovaSeq X flow cells can generate ≥85% of bases at Q40 or higher (99.99% accuracy), in comparison to the Q30 standard of prior sequencers. By
late 2023 Illumina enabled 2×300 bp reads on NovaSeq X flow cells (primarily for microbiome and metagenomics users needing longer coverage). Additionally, Illumina has back-ported XLEAP-SBS to mid-range instruments. An early 2024 update allows NextSeq 1000/2000 systems to use XLEAP-SBS with new P4 flow cells (~500 Gb output), indicating Illumina’s intent to make the chemistry standard across its lineup.
Complete Genomics: DNBSEQ with CoolMPS and HotMPS Chemistries (mature by 2025)
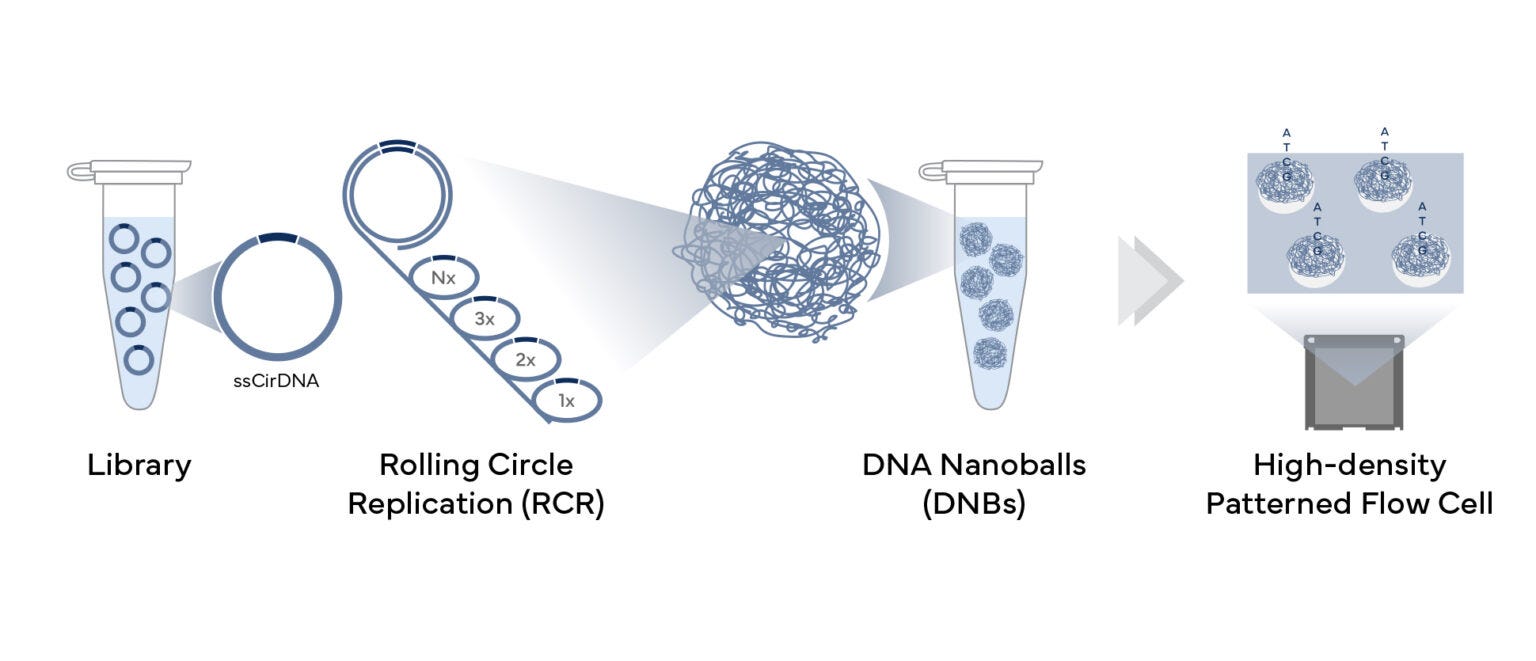
Complete Genomics’s sequencing platforms are built around a core technology called DNA Nanoball sequencing (DNBSEQ). Unlike other short-read platforms that use bridge amplification, MGI circularizes DNA fragments and amplifies them using rolling circle replication. This produces compact DNA nanoballs, each consisting of hundreds of identical copies of a single DNA molecule. These nanoballs are then loaded onto a patterned flow cell at high density, with each occupying a precise, separate position. Because each nanoball contains many copies of the same fragment, signal averaging becomes highly effective, allowing for accurate base detection with minimal cross-talk between spots.
Traditionally, MGI sequencers used a sequencing-by-synthesis (SBS) approach similar to Illumina’s, with fluorescently labeled nucleotides added one base at a time and imaged to determine the sequence. However, MGI has developed two distinct chemistries to further improve speed, accuracy, and data quality: HotMPS and CoolMPS.
HotMPS is an updated version of SBS that uses directly labeled nucleotides with enhanced polymerase enzymes. The chemistry has been optimized to reduce incorporation bias and fluorescence noise, delivering faster cycle times and improved base-calling accuracy. It's the default chemistry for high-throughput runs on platforms like the T7 and T20, where large-scale projects require both speed and scalability.
CoolMPS, by contrast, takes a different approach. Rather than using fluorescently labeled nucleotides, CoolMPS incorporates unlabeled bases during sequencing. After each incorporation step, fluorescently labeled antibodies that specifically recognize the incorporated base are added to detect which base was added. This indirect detection strategy reduces chemical "scarring" and dye-related artifacts, resulting in cleaner signal and longer read lengths with fewer errors. Because the nucleotides themselves are unmodified, polymerase activity is more consistent and incorporation fidelity is higher.
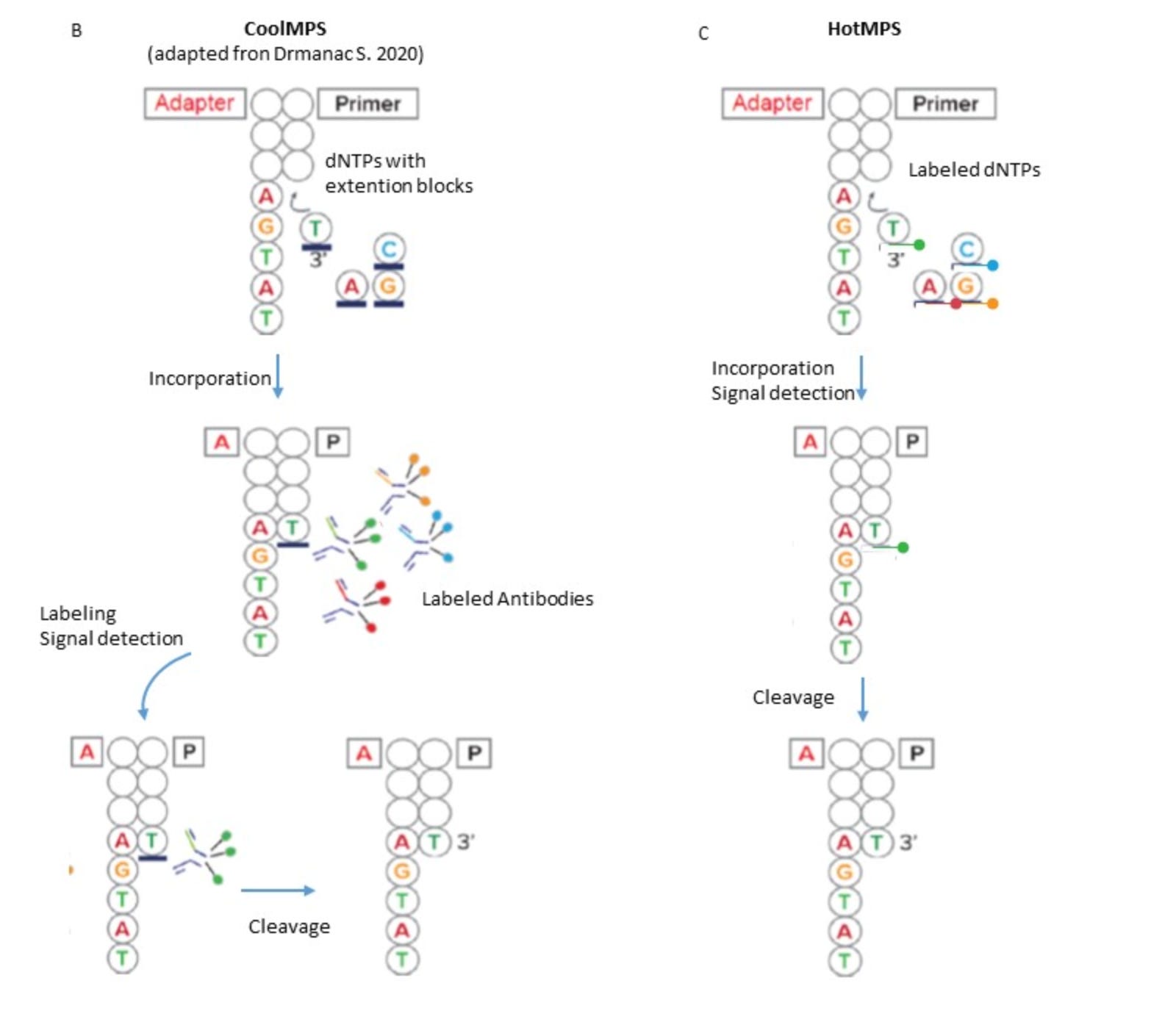
Together, these chemistries support read lengths up to 2×300 bp, with over 85% of bases typically achieving Q30 quality. On the highest-end system, the DNBSEQ-T20×2, MGI platforms can output up to 72 terabases in a single 80-hour run, currently the most in the industry! This scalability, paired with high accuracy and unique chemistry options, makes MGI a strong contender in applications like population-scale genomics, clinical diagnostics, and spatial transcriptomics.
GeneMind: Lightning Chemistry (launched 2024)
GeneMind’s SURFSeq Q uses classic sequencing-by-synthesis (SBS) on patterned flow cells, where DNA fragments amplify into dense, equally spaced clusters across the chip. Each cycle, fluorescently labeled nucleotides are added to the clusters, imaged, and then cleaved to read the next base, the same core process as Illumina-style sequencers.
To significantly boost both speed and quality, GeneMind introduced Lightning Chemistry in 2024. This chemistry improves three core areas: signal clarity, cycle speed, and base-calling accuracy. Brighter fluorescent labels and refined polymerase enzymes allow faster and cleaner nucleotide incorporations. The combination enables ultra-high throughput. SURFSeq Q delivers up to 14 Tb per run (≈9 Tb/day), while maintaining exceptional accuracy, with 90% of bases at Q40 or higher.
Ultima Genomics: Solaris with ppmSeq (launched 2025)
Ultima Genomics takes a unique approach to short-read sequencing by replacing traditional flow cells with a spinning silicon wafer etched with billions of tiny nanowells. Each well is designed to hold a single DNA fragment, which is anchored using special adapters during library preparation. Once loaded, the wafer spins rapidly to distribute sequencing reagents evenly across its surface, a process that also minimizes fluidic complexity and speeds up reaction cycles.

Ultima’s sequencing chemistry follows a method called sequencing-by-addition. Instead of flowing in all four nucleotides (A, T, C, G) at once (as is common in sequencing-by-synthesis platforms) Ultima flows only one base at a time. For example, in the first cycle, only adenine (A) nucleotides are introduced. If the complementary base on a DNA fragment is thymine (T), the polymerase incorporates an A and emits a fluorescent signal. If not, no incorporation occurs and no signal is recorded. This single-base flow cycle is repeated sequentially (A, then C, then G, then T) across hundreds of cycles to reconstruct the DNA sequence one base at a time.
To enhance basecalling accuracy, especially in error-prone regions like homopolymers, Ultima employs a proprietary method called ppmSeq (plus/minus strand sequencing). This technique sequences both strands of the same DNA molecule independently. The forward and reverse reads are then compared, allowing the system to detect and correct mismatches or insertion-deletion (indel) errors. By cross-validating the two strands, Ultima improves variant calling accuracy and read confidence without sacrificing speed or cost.

Thanks to its simplified chemistry and real-time error correction, Ultima achieves variant-calling performance comparable to short-read leaders like Illumina, with base-level Phred quality scores approaching Q30-Q40, or 99.9% to 99.99% accuracy.
Singular Genomics
Singular Genomics’ G4X platform introduces a hybrid of high-throughput sequencing and spatial biology in a single system. At its core, G4X uses sequencing-by-synthesis (SBS), where fluorescently labeled nucleotides are incorporated one base at a time and recorded by an optical system. But what sets G4X apart is its ability to perform in situ sequencing directly on preserved tissue samples, using a method called Direct-Seq.

With Direct-Seq, FFPE (formalin-fixed paraffin-embedded) tissue sections can be sequenced without the need to extract and convert RNA into cDNA. Instead, the nucleic acids remain physically anchored in the tissue, and sequencing happens right where the molecules naturally reside. This is achieved by flowing specially designed polymerases and fluorescent nucleotides over the sample. As the enzyme incorporates each nucleotide, it emits a flash of light that is recorded by the instrument’s camera, identifying the added base and its precise location within the tissue.
This direct sequencing preserves spatial context while revealing gene expression, allowing researchers to detect RNA transcripts without disrupting the surrounding tissue architecture. In parallel, the G4X system can also perform protein detection using fluorescently tagged antibodies and identify genomic variants, such as single nucleotide changes or small insertions and deletions, from the same section.
By layering RNA, protein, and mutation data into one integrated dataset, G4X is the first to enable full spatial multi-omic profiling in the same sequencer.
Short-read platforms are adding long-read capabilities.
Historically, short-read sequencers like those from Illumina dominated the market with high accuracy and massive throughput, but they struggled to resolve complex regions of the genome due to limited read lengths. To overcome this, Illumina introduced Complete Long Reads (CLR), a synthetic long-read approach that uses molecular barcodes to tag long DNA fragments, which are then sequenced as short 2×150 bp reads and computationally stitched back together.
This enables users of NovaSeq X and 6000 to generate long-read-like data without investing in new hardware. The reconstructed long reads achieve Q30-Q40+ accuracy (99.9-99.99%).
Other short-read companies are following a similar strategy. Element Biosciences, for instance, acquired Loop Genomics to offer barcode-based long-read reconstruction on the AVITI platform. The platform’s native short-read chemistry already reaches Q40 accuracy (99.99%), making it well-suited for high-precision long-read assembly.
These developments reflect an interesting trend. Short-read platforms are expanding into long-read territory by offloading complexity to molecular barcoding and software, while preserving the accuracy and cost-efficiency advantages of short-read sequencing.
Long-read platforms are also doing short-reads.
Oxford Nanopore Technologies (ONT) introduced Short Fragment Mode to support DNA fragments as short as 200-500 bp, enabling workflows with degraded or low-input samples like FFPE tissue or microbial DNA. Combined with Duplex Sequencing, which boosts accuracy by sequencing both strands of a molecule, ONT now supports applications once reserved for short-read platforms.
PacBio launched Onso, a dedicated short-read sequencer using a novel sequencing-by-binding chemistry. Instead of incorporating nucleotides, this approach detects fluorescently labeled bases as they bind reversibly to the template strand, reducing signal noise and improving accuracy. Onso achieves Q40+ accuracy and is aimed at precision-focused markets like oncology and NIPT.
Though these are technically impressive developments, it’s still unclear whether long-read companies can compete head-on in the short-read market. ONT’s and PacBio’s efforts appear more like adaptations to support existing users, those who already own a MinION or Revio, and want to handle occasional short-read workloads, rather than serious attempts to replace Illumina or AVITI for core short-read use cases.
Comparison by Attribute
Disclaimer: This section is built on our CSV, which aggregates public and online information. While some providers have transparent spec sheets on their websites, others don’t and require direct sales contact. In such cases, we tried our best to provide estimates. Please reach out to hannah@latch.bio to propose any corrections.
The U.S. seems to be trailing behind Chinese manufacturers in terms of throughput and speed.
One headline metric is maximum data output (throughput). This determines how many samples or how deep a sequencing run can go in a given time.
The current champions in output are Complete Genomics’s DNBSEQ-T20 (or T10 or T7), Illumina’s NovaSeq X, GeneMind’s SURFSeq Q, ONT’s PromethION 48, and Ultima’s UG 100 - all capable of multi-terabase outputs per run:
DNBSEQ-T Series: Topping the chart is Complete Genomics, a subsidiary of Complete Genomics in China, which dominates when it comes to throughput per day. Their DNBSEQ-T20 instrument yields 72 Tb data for one 80-hour run, translating to ~21.6 Tb/day. The T10 variant achieves even higher total output at 76.8 Tb per run over 106 hours (~17.4 Tb/day), while the T7 offers 7 Tb in 24 hours (7 Tb/day).
SURFSeq Q: GeneMind's high-end platform achieves an impressive 14 Tb total output in just 36 hours, translating to over 9.3 Tb/day. This positions it as the second-fastest daily throughput platform, though with lower total capacity than the largest MGI systems. A smaller SURFSeq configuration matches the DNBSEQ-T7 at 7 Tb/day.
NovaSeq X Series: Illumina's flagship production platform delivers up to 16 Tb per run in 48 hours, achieving 8 Tb/day at peak configuration. Multiple flow cell options provide flexibility, with smaller configurations generating 3-8 Tb per run. The platform balances throughput with established ecosystem support, though it trails MGI's peak daily rates.
UG 100: Ultima Genomics' cost-focused platform generates 3.6 Tb per run in 12-14 hours, achieving approximately 6.2 Tb/day. While lower in absolute output, this platform targets the $100 genome milestone through exceptional cost efficiency rather than maximum throughput.
PromethION Series: Oxford Nanopore's long-read flagship achieves 7 Tb total output but over 72-hour runs, resulting in 2.3 Tb/day for the 24-flow cell system. The 2-flow cell variant produces 580 GB over similar timeframes. While lower in raw throughput, these platforms enable applications impossible with short-read systems through ultra-long reads exceeding up to 4 MB.
In the upper quadrant of the market, we have Ultima Genomics’ UG100 ($1.5M), Illumina’s NovaSeq X ($985,000) and NovaSeq X Plus ($1.25M), with NovaSeq 6000 having a similar price tag as NovaSeq X, but with a different range of throughput. Complete Genomics’s DNBSEQ-T7 especially stands out, since it delivers 7 Tb/day—nearly matching NovaSeq X Plus’s 8 Tb—but costs only ~$600K, half the price. Even in the mid-throughput range, DNBSEQ-T1+ comes at $299,000, almost a third of the cost of a NovaSeq 6000. (Note: Complete Genomics doesn’t publish its costs online, but these prices have been confirmed by a representative from Complete Genomics)
The market is heavily clustered in the low-to-mid throughput and cost range. Let’s zoom into them.
In the low-throughput range, most instruments output under 500 Gb/day, with a wide spread in pricing. Illumina offers the broadest lineup—from the low-cost iSeq to the mid-tier NextSeq 1000—ranging from ~$20K to over $300K. Oxford Nanopore and Thermo Fisher offer alternatives like MinION, GridION, and Genexus, with varying form factors and costs around $100K–$300K.
Element Biosciences and Complete Genomics enter at slightly higher throughput levels (100–400 Gb/day) with machines priced near $300K–$400K, offering better output per dollar. PacBio’s Revio is the clear outlier (producing ~400 Gb/day at ~$600K) but includes HiFi accuracy and native methylation calling, justifying its premium.
Scientists need to navigate the cost per genome vs instrument price paradox.
The most expensive machines often deliver the lowest cost per genome, while affordable instruments can carry surprisingly high per-sample costs. You can achieve low cost per gigabase, but only with instrument investments in the millions of dollars range. Looking at cost per genome alone can be misleading.
Below, we compare cost per genome across various providers on the market. To calculate cost per genome, we:
Gather maximum data yield per run from instrument provider websites
Obtain maximum reagent cost per run from provider websites or news report estimates when unavailable
Calculate cost per gigabase = maximum reagent cost ÷ maximum data yield
Assume 30X genome coverage requiring approximately 100 Gb of sequencing
Calculate cost per genome = cost per gigabase × 100
In the realm of short-read sequencing, leading this race is Ultima's $1.5M UG 100, which achieves the lowest cost at $80 per genome, while Illumina's $1.25M NovaSeq X delivers $103-268 per genome depending on configuration.
Complete Genomics doesn’t sell their DNBSEQ-T20 directly. Instead, pricing is amortized over reagent contracts (e.g., $0.99/Gb for 72 Tb/run or $99/per genome), good for mega-scale centers sequencing >50k genomes/year.
In the middle tier, platforms like the NovaSeq X 1.5B, DNBSEQ-T7, and AVITI strike a balance between upfront investment and per-genome cost. These instruments typically fall in the $300K to $1M range and bring sequencing costs down to around $150-300 per genome. They’re a good fit for labs that don’t need ultra-high throughput but still want to process thousands of samples a year efficiently. Many offer flexible flow cell configurations, so you’re not locked into massive runs to make the economics work.
Element Biosciences' AVITI emerges as a fierce contender in the mid-range market. At $289,000, the instrument delivers $200 per genome costs that directly compete with Illumina's NovaSeq X 25B ($206 per genome) while requiring less than one-third the capital investment ($985K for NovaSeq X). Even AVITI's lower-throughput configurations maintain competitive economics, with cost per gigabase ranging from $5.60-$7.20, closely matching the NovaSeq 6000's $4.55-$6.23 range across S1, S2, and SP flow cells. This positioning allows institutions to access near-production-scale economics without the substantial upfront investment typically required for high-throughput sequencing.
While short-read platforms continue to drive costs down across a range of throughput tiers, long-read technologies are following close behind, offering increasingly competitive pricing with the benefit of spanning complex regions.
Long-read whole-genome sequencing costs are difficult to pin down because they hinge on several interacting factors. While Oxford Nanopore advertises roughly $345 for about 100 Gb and PacBio quotes around $500 for ~30× human genome coverage on its Revio system, actual price depends on flow-cell yield (Nanopore flow cell output ranges from ~100 Gb to 290 Gb), the accuracy mode chosen (cheaper Q20 simplex reads versus higher-quality Q30+ duplex reads), and application-specific depth or accuracy requirements.
Is Cost per GB all that matters? Beware of hidden infrastructure costs.
Converting electrical signals and optical data into usable format is no easy task. While cost per gigabase has become the dominant metric for comparing sequencing platforms, this narrow focus obscures the substantial computational infrastructure investments required to transform raw sequencing data into useful insights.
Once bases are called, labs must invest in compute infrastructure, software licenses, data transfer pipelines, storage, and ongoing maintenance to extract value from the output.
What do these hidden costs include?
Primary analysis: basecalling, demultiplexing
Secondary analysis: alignment, variant calling, assembly
Data storage: terabytes of raw + processed data per run
Compute infrastructure: on-prem clusters or cloud credits
Software licenses: proprietary tools (e.g. DRAGEN)
Data transfer: ingress/egress fees for cloud platforms
Compliance: secure, reproducible pipelines for CLIA/CAP/ISO especially for diagnostics use cases
At AGBT 2025, Illumina CEO Jacob Thaysen captured this shift:
"Customers are not only buying a product anymore…they're buying into a whole ecosystem… applications, workflows, informatics… That is the game."
Below, we compare how major sequencing vendors address these hidden infrastructure costs through engineering design and software strategy.
DRAGEN: FPGA-accelerated genomics
Illumina recognized the challenges in storage and processing of genomic data early, acquiring Edico Genome and the DRAGEN Bio-IT platform in 2018 to architect a solution.
DRAGEN uses highly reconfigurable field-programmable gate arrays (FPGA) to provide hardware-accelerated implementations of genome analysis algorithms, reducing processing time for a 40× whole human genome from over 8 hours with traditional open-source solutions to approximately 34 minutes.
The engineering behind DRAGEN's performance is also quite interesting. The NovaSeq X Plus features dual socket AMD EPYC 7552 processors with 96 x86_64 cores, four Xilinx Alveo U250 FPGA cards, and 1.5 TB of RAM, enabling on-instrument DRAGEN processing to output fully processed 30× WGS samples approximately once every four minutes while drawing power from a single standard 200-240 volt AC plug (about the same energy required to propel a Tesla Model 3 half a kilometer). The resulting compute cost averages <10 US cents.
However, DRAGEN's impressive technical capabilities come with significant licensing costs. Since Illumina doesn't benefit from FPGA hardware sales, they've adopted an aggressive software licensing model. When running DRAGEN on cloud platforms like AWS, the license cost represents approximately 80% of the total computational expense, a pricing structure that can make cloud-based processing prohibitively expensive for large-scale projects.
Oxford Nanopore and PacBio Revio: Onboard GPUs right inside the device
Oxford Nanopore takes a different approach by building GPUs directly into its high-throughput sequencers, so there’s no need for separate compute clusters or extra software to process the data.
The PromethION P48 now comes with four NVIDIA A100 GPUs, which speed up basecalling by more than 50% compared to older models. This means the sequencer outputs already basecalled data. You get usable FASTQ files right off the machine, ready for analysis. Each run can generate up to 10-13 terabases of data over 72 hours. And because the data is processed in real time on the device, there's no need to move massive raw signal files (which can be 2-3X larger) to the cloud or external servers.
Similarly, PacBio’s Revio also includes onboard NVIDIA A100 GPUs. The system handles basecalling, error correction, and consensus (HiFi) reads on-device, delivering BAM/FASTQ files ready for analysis.
Each SMRT Cell produces ~120 gigabases in ~24 hours. With four cells in parallel, that's up to 480 Gb/day, enough for 1,300 human genomes per year at 30× coverage, all for under $500 per HiFi genome using their SPRQ chemistry and reagent pricing.
Element cloud-first strategy
Element's AVITI platform integrates natively with Amazon Omics, streaming data directly to customer S3 buckets during sequencing and enabling immediate parallel analysis without costly subscription services or intermediate data transfers. Bases2Fastq Ready2Run workflow on Amazon Omics costs approximately $3 to generate FASTQ files for a 300‑G base run (2×150 bp) and completes in about 1 hour for demultiplexing, with the full pipeline (FASTQ → BAM → VCF) finishing in ~2 hours.
Ultima’s hybrid approach
Each UG 100 sequencer comes with built-in high-performance compute that runs standard pipelines like basecalling, alignment, and variant calling directly on the instrument. For downstream analysis, users can upload the output to the cloud and run Ready2Run pipelines on AWS HealthOmics, including DeepVariant ($2 per genome in US regions), Sentieon DNAscope, and GATK workflows. For advanced users, Ultima offers open-source Terraform and WDL modules that make it easy to deploy private workflows using their own AWS storage, compute, and custom references.
Software competitiveness will become more important in the future.
As companies integrate with more multi-omics modalities and become more verticalized, building an ecosystem of robust bioinformatics tools and doing so fast will be important. Prime example is Illumina who’s leading this trend by releasing the Integrated Connected Multiomics platform.
The dynamics in the sequencing market mirror the early smartphone era: As genome sequencing costs plummet, the device matters less than the ecosystem of multiomics kits and tools around it.
Platforms that simplify the transition from raw data to insight will ultimately win the loyalty of users long-term.
Multi-omics Support: Are sequencing machines evolving into something more?
What began as instruments designed to read DNA has quietly transformed into something far more ambitious: platforms that can simultaneously peek into multiple layers of cellular life. Instrument providers seem to be asking a new question: not only "how fast can we sequence DNA?" but also "how completely can we understand a cell?"
This paradigm shift became clear in February 2025 when Illumina announced their spatial technology program. Rather than just reading sequences, their platform maps entire transcriptomes while preserving the spatial context, profiling millions of cells on two slides, supported by Connected Multiomics software designed for researchers without bioinformatics expertise.
Singular had already signaled this direction a year earlier with their G4X announcement in February 2024. Their instrument handles both traditional sequencing and spatial analysis seamlessly. Through Direct-Seq technology, they read RNA directly within intact FFPE tissue without library preparation, simultaneously detecting transcripts, imaging proteins, and reading mutations while maintaining spatial context. Early users have demonstrated 3D tissue reconstructions analyzing over 6 million cells from a single flow cell.
Element also pushed this concept with their AVITI24, performing what they call "5D multiomics": simultaneous detection of DNA, RNA, proteins, phosphorylated proteins, and cell morphology from the same sample in under 24 hours. Their upcoming Direct In Sample Sequencing eliminates library prep entirely by targeting RNA molecules directly within cells. Teton assays focus on specific pathways, currently targeting 350 genes and 50 proteins in MAPK signaling.
PacBio completed this picture with their SPRQ chemistry, launched late 2024. Using 6mA markers in Fiber-seq, every run becomes multiomics by default, simultaneously calling DNA sequence, methylation, and chromatin accessibility. Researchers can extract four molecular views (genome, methylome, epigenome, and transcriptome) from a single sample.
Instrument makers are racing to integrate upstream prep and downstream analysis directly into their platforms through aggressive acquisitions and internal development. Illumina acquired Fluent BioSciences mid 2024 to bring single-cell library prep in-house, then followed with a $425M acquisition of SomaLogic mid 2025 to add proteomics assays to its sequencing ecosystem. Thermo Fisher made a similar move by acquiring Olink for $3.1B late 2023, expanding into high-throughput protein biomarker analysis. Meanwhile, Complete Genomics has internally developed a full-stack system that includes its DNBSEQ sequencing platforms, MGIFLP library prep systems, and a growing multi-omics portfolio spanning spatial transcriptomics, methylation, whole-genome sequencing, single-cell, exome, and proteomics applications.
Starting as DNA readers, these instruments increasingly look more like a “cellular omniscope”, aiming to capture multiple modalities of a cell’s biology.
Read Length
Different applications demand different read lengths. The table below summarizes recommended configurations and throughput per sample for common short-read workflows:

Most short-read sequencing platforms today use a 2x150bp format, which means they sequence 150 bases from each end of a DNA fragment. It also aligns well with common DNA fragment sizes used in WGS libraries, which typically range from 350 to 400 bp. Leading high-throughput instruments, including Illumina's NovaSeq X, Complete Genomics' DNBSEQ-T7/T1+, and GeneMind's SURFSeq Q, all use this 2×150bp configuration.
Mid-throughput instruments like the NextSeq 2000/1000 and MiSeq i100 can support 2×300bp reads, but this extended read length comes at the cost of reduced throughput. This trade-off stems from fundamental limitations in Illumina's sequencing-by-synthesis (SBS) chemistry and bridge amplification process.
Illumina's bridge amplification requires both ends of a DNA fragment to attach to the flow cell surface, forming a bridge structure. The DNA then undergoes in-place amplification to create clusters of identical fragments. This process works optimally with shorter DNA fragments because longer fragments struggle to achieve the necessary flexibility for both ends to efficiently bend and hybridize to the surface. When bridging fails, fragments cannot amplify into clusters, resulting in reduced cluster density, weaker signal intensity, and lower overall yield.
On the contrary, new players in the field such as Roche are breaking the trend with their new SBX system that’s in R&D. Roche promised in their AGBT presentation with “simplex reads ranging from 50 bp to >1,000 bp”, “duplex reads (~150–350 bp inserts) delivering intramolecular consensus with Q39 accuracy”, and even “midi reads reaching 1,200-1,500 bp for longer contiguous coverage. SBX also claims it can sequence 7 human genomes (30× depth) in just one hour, over 5 billion duplex reads per hour. These newer players are likely putting competitive market pressure on Illumina as they are likely bringing the best from both worlds: supporting longer fragments, and while also enabling high-throughput sequencing.
Parting Thoughts
The sequencing landscape in 2025 reflects several converging trends.
Sequencing providers are rapidly verticalizing, transforming from instrument vendors into “full-stack” companies that control everything from sample prep, assays, to data interpretation and insights.
The traditional boundaries between short and long reads continue to blur. Short-read platforms now generate synthetic long reads through molecular barcoding, while long-read companies launch dedicated short-read instruments. Mid-length chemistries promise to bridge the gap with kilobase reads at short-read accuracy levels.
The relentless drive toward lower cost per gigabase shows no signs of slowing. The $100 genome milestone is within reach, with Ultima targeting even lower thresholds potentially approaching $50 per genome by the late 2020s. As reagent costs become commoditized, ecosystem support may emerge as the primary differentiator over raw sequencing economics.
Long-read technologies are poised for clinical adoption as accuracy improvements and cost reductions to <$1000 per genome make long-range genomic profiling possible. The vision of single-platform workflows capturing SNPs, structural variants, methylation, and RNA expression simultaneously is materializing through providers' push for better enhanced chemistry and error correction algorithms.
Finally, sequencers are becoming multiomics platforms. These instruments now capture DNA sequence alongside spatial context, protein abundance, and epigenetic modifications in single runs.
All roads still lead to sequencing machines. But these machines are becoming far more powerful than their original architects ever imagined.