
Forch: Bring-Your-Own-Compute on Latch
Motivation, design and deployment details of a new compute orchestrator

In the past few years, it became clear we were fighting Kubernetes more than we were benefitting from it. The orchestrator seems well suited to largely static workloads where a small number of services are running constantly on a set of very similar nodes. Our perfect solution looks like the exact opposite of that. We want to run a lot of short-lived tasks, ranging in duration from seconds to days. We also want to optimize for availability, by including as many compute instances as we can get our hands on, without concern for what hardware they are running or what cloud provider they come from. Ideally, any computer with an internet connection can join the cluster and run workloads, even if it exists in a customer’s existing cloud infrastructure. To accomplish this, we built a new compute orchestrator called Forch.
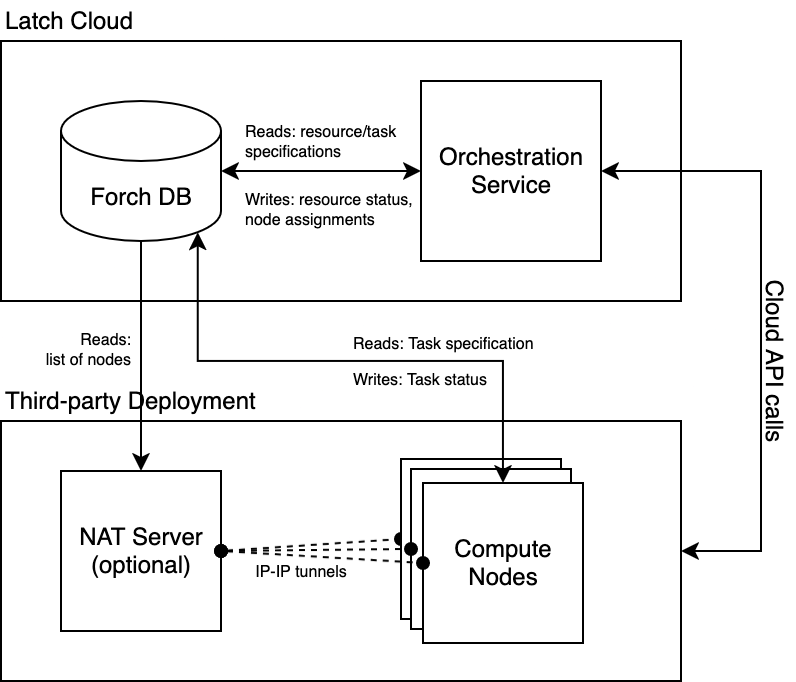
Overview
Forch has native support for cross-region (and even cross-cloud) deployments. This brings improved network latency for Latch Pods/Plots and other interactive software for users outside the US west coast, where our compute is currently hosted. It also gives us access to a much larger pool of instances - when the AWS datacenter in Oregon runs out of A100 GPUs, we can opt to get some from GCP in Utah. We can even choose the location by comparing prices of all suitable instances across all regions of all providers, bringing a potentially significant reduction in cost.
It should also be possible to eventually support on-prem deployments as it doesn't make a difference to the orchestrator where the computer is located. Forch is designed to avoid up-front requirements for its compute nodes and their environment. For example, if you never run a task which wants to accept internet connections, you never have to worry about the public IP allocation system or firewall configuration. The Forch components responsible for these features will never run. If the on-prem nodes happen to already have storage devices attached to them, Forch tasks can use the devices without a storage device driver in the orchestrator itself. This means we can automatically support environments without cloud APIs.
As opposed to our Kubernetes setup, Forch does not choose from across pre-defined "node groups". Instead it queries the cloud providers directly for all available instance types and chooses according to a scoring formula. This means that not only is the cost reduced by choosing the best location, even the type of the instance is chosen based on price. Moreoever, Forch uses a generic constraint solver to decide which tasks will run on which nodes, allowing for for very complicated requirements and preferences. For example, you could encode data egress costs (based on estimated task input size) and include them in the price estimate for a given instance. In our Kubernetes set up (if it supported multiple clouds) you would have to manually check the instance prices, estimate egress costs, and make a decision ahead of time. By the time the task was running, the instance prices or availability might also be different, especially when using preemtible spot instances.
We also designed Forch to be easy to debug and maintain. Our experience running Kubernetes has been plagued by errors that are specific to the interaction between various semi-compatible versions of its plugins and the idiosyncracies of AWS EKS (our provider), the Kubernetes resource abstraction, and Go (its implementation language). Commonly, the only error exposed by Kubernetes APIs is the dreaded "context deadline exceeded" which means that something somewhere timed out and we have to scan through millions of lines of logs across dozens of services to find relevant information. Forch is built around a central database which stores the entire history of state transitions for all objects, which are themselves immutable. It is always possible to figure out how the state of the system evolved over time to get to an error. We also include OpenTelemetry-based distributed tracing in all our services to make sure we have very complete, structured information about the actions that Forch takes at the code level.
Deploying Forch
We are working on making Forch as easy to deploy in a third-party cloud account as possible. The current setup involves provisioning an AWS CloudFormation template which creates a setup role, which is passed to a Pulumi deployment to configure a dedicated VPC and other downstream roles. After the initial setup, the CloudFormation role can be optionally revoked as the Forch will use fine-grained roles managed by Pulumi. We expect to provide more flexible deployment options (using an existing VPC, or without any custom AWS IAM permissions) in the future.
In its current form, Forch assumes an IAM role in the target AWS account to issue API calls. We plan to eventually introduce a security barrier in the form of an "Agent" service which runs in the target account itself and acts on behalf of the orchestrator. This service will be fully controlled by the account owner and Forch will no longer require users to grant any permissions to the Latch AWS account.
We currently expect users to use a Latch-provided AWS EC2 AMI for the compute nodes though in practice there are only two requirements for a computer to join the cluster:
1. a Python runtime (typically with uv),
2. an internet connection of some sort (egress only being acceptable).
All features that require cloud APIs are designed to be optional as they may not be necessary for some users and require additional setup, account permissions, and potentially impose limitations on the compute environment. Forch currently supports the following:
Task IPv6
Forch will configure IPv6 addresses for each task if the node's network card reports an assigned IPv6 prefix. This is used by Latch Pods.
Task Firewalls
Forch configures firewalls using nftables on each node to prevent communication between the tasks, the tasks and local networks, and the tasks and the internet. These are fully configurable and allow rules based on specific IPs and task IDs (which resolve to the tasks' current IPv6 addresses). This is used by Latch Pods.
Example configuration (database rows):
task_id=1 peer_task_id=2 direction='ingress'
-- allow task #1 to receive traffic from task #2
Node Mounts
Forch allows tasks to request directories from the node are bind-mounted into the task. This is currently only available to "privileged" tasks. You may request privileged tasks only on nodes for which you have additional authorization explicitly for this feature. Forch currently uses this internally to implement NFS server tasks.
Example configuration (database rows):
-- note: the task must have privileged=true
task_id=1 src_path='/dev' mount_path='/dev' mount_propagation='rshared'
-- allow the task to access the parent node's /dev directory
Task Configuration
Forch allows passing configuration data to tasks in environment variables or injected files. The data is stored in plain text in the Latch-owned central database so is not suitable for secrets or sensitive information. This is used for all Latch workloads.
Example configuration (database rows):
-- task_datum_spec:
id=1 dest_environment_variable='TEST' src_inline='hello world'
id=2 dest_path='/config.json' src_inline='{"hello": "world"}'
-- task_data:
task_id=1 datum_spec_id=1
-- task #1 receives data from spec #1 (TEST='hello world')
task_id=1 datum_spec_id=2
-- task #1 receives data from spec #2 (file /config.json)
Task Secrets
Forch can use external secrets management APIs to securely pass secrets to the tasks in environment variables or injected files. The secrets are absolutely never read outside the compute node running the task requiring the secret. This is used for all Latch Pods.
We provide an AWS SecretsManager driver. This feature requires respective AWS permissions.
Example configuration (database rows):
-- secret:
id=1 provider_id='secret-key' infra_provider='aws' infra_account='000000000000'
-- task_datum_spec:
id=1 dest_environment_variable='KEY' src_secret_id=1
-- task_data:
task_id=1 datum_spec_id=1
-- task #1 receives data from spec #1 (KEY=<REDACTED>)
Node Autoscaling
Forch is able to determine when new nodes are required to run tasks and automatically request new nodes. It is also able to detect empty nodes and request their shutdown after a cool-down period. This is used for all Latch workloads.
We provide an AWS EC2 driver. This feature requires respective AWS permissions.
Forch also allows specifying a schedule anticipating expected demand by day+hour and Forch will scale up nodes in advance to ensure demand can be fulfilled.
Public IPs
Forch can assign public IPs to tasks, if they require routing for incoming connections. We use this internally to implement Latch Pods.
We support nodes with public IPv6 and IPv4 addresses (any number of assigned addresses would work).
We also provide an AWS Elastic IP driver. Forch also provides a custom NAT server to support using Elastic IPs with nodes from a private VPC subnet (i.e. the nodes do not have a pre-assigned public IP). This feature requires respective AWS permissions.
Example configuration (database rows):
-- ip:
id=1 provider_id='eipalloc-00000000000000000' infra_provider='aws' infra_account='000000000000' infra_geo_partition='us-west-2'
-- task_ip:
task_id=1 ip_id=1
-- task #1 will have IP address #1 (provided by AWS Elastic IP with allocation `eipalloc-00000000000000000`)
Storage Devices
Forch allows tasks to mount external devices for persistent storage. This is used in Latch Pods. For ephemeral storage you can use the node's storage devices. This is used for Latch Pods.
We do not currently support placing ephemeral storage on dedicated volumes, but this may change in the future.
We provide an AWS EBS driver which additionally supports volume resizing. We plan to eventually provide volume pre-warming and cross-region/AZ copying. You must create the volumes externally and provide the volume ID to Forch, but this is typically a single API request. This feature requires respective AWS permissions.
Example configuration (database rows):
-- storage_device:
id=1 provider_id='vol-00000000000000000' infra_provider='aws' infra_account='000000000000' infra_geo_partition='us-west-2'
-- task_storage_device:
task_id=1 dev_id=1 mount_path='/mnt' mount_type='filesystem'
-- task #1 will have device #1 (EBS volume `vol-00000000000000000`) mounted to /mnt
-- the node will ensure a filesystem is present on the device before the task starts
Cuda Devices
Forch nodes can attach CUDA devices to tasks, when available. They will also mount the node's CUDA drivers/SDKs into the tasks since the driver version has to match exactly between a container and the host.
Example configuration (database rows):
-- task:
display_name='test' ... dedicated_gpu_type='A10G' dedicated_gpu_count=1
-- task "test" will only run on nodes where an A10G is available
-- the device will be provided to the container along with the CUDA driver
-- using bind mounds from the host
Billing
Forch allows tracking the runtime of tasks and "charging" it to an entity by ID. The task creator must provide authorization to charge to a specific entity. This is used internally by Latch to implement billing.
Architecture Overview
The core components of Forch are:
The database (Postgres)
The orchestration service
The node daemons
The NAT servers (per VPC/networking environment)
The orchestrator handles scheduling using constraint solving and executes various environment control API calls e.g. attaching/detaching AWS EBS devices.
In the future, we plan to add an additional "Agent" service which will handle cloud API requests and other environment configuration functions which are currently assigned to the orchestration service. This is to improve permission separation by allowing Forch to function without holding permissions delegated from the compute environment e.g. with an externally-assumable AWS IAM role.
The node daemons send requests to the local container runtime based on tasks read from the database. They also handle system-level setup like firewall configuration (using nftables), storage device preparation (partitioning, file system creation for new devices).
All the services communicate exclusively through polling the database for new rows. Authorization is implemented in-database using row-level security functions, predicated on ED25519 JWKs verified by a plv8-packaged JS implementation. There is no API server, though Latch uses its existing API servers for creating workloads and workload resources (i.e. operating the Forch cluster). User-owned deployments will not need to interact with these services.
The NAT server works by setting up IP-IP tunnels to each node and configuring nftables. This is generally optional, depending on the networking setup. It was originally introduced because the AWS Elastic NAT service cannot be used with Elastic IPs since none of the available Route Table configurations route traffic appropriately. It should be rarely necessary outside of this setup.
Our database schema is based around immutable objects holding configuration for various resources (like provider-specific IDs e.g. AWS EBS volume IDs), and the associated event tables, which hold a parent object ID, timestamp, and type + their event data tables, which hold the data specific to each event type. The state of each object (e.g. if a storage device is attached to a node) is determined by taking the latest event and looking at its type and/or data. We hold the entire history of all state transitions of all objects for observability/debugging purposes.
All services are also traced using OpenTelemetry/Datadog. This is a huge improvement over the infamous Kubernetes/Go "context deadline exceeded" set of errors.
Using Forch
Latch users can look forward to Forch being enabled globally in 2026. For the time being, Forch is already available with explicit opt-in. Users can choose one of several Latch-owned deployments in various AWS regions and we will bring up more regions and other cloud providers over time based on demand. We are working with select partners to make user-owned cloud compute environments generally available by the time Forch rolls out to the public.
If you are interested in Forch, please reach out to contact@latch.bio or on social media.
We may publish detailed posts focused on the engineering behind Forch in the future. Please reach out to kenny@latch.bio or on social media if you are interested so we can prioritize topics accordingly.
 | A guest post by
|