
How biotechs use software to make drugs
The realistic use of data infrastructure to develop a PCSK9 binding antibody from ideation to IND

Modern biotechs are industrial research labs and complex human engineering projects that must both fight nature and coordinate diverse scientific teams before running out of money.
There are few resources that breakdown the structure of a biotech company and show how experimental data flows between teams for each concrete step of a drug development campaign. In this essay, we construct a fictional but realistic company developing antibodies for cardiovascular disease and walk through an end-to-end drug discovery campaign, from ideation to IND.

At each step, we use realistic biological details to describe how specific software components are used to coordinate teams, understand more biology from data and increase the economic productivity of the entire organization.

Building an Antibody to Reduce Blood Cholesterol
Cardiovascular disease continues to plague humanity and is the leading global cause of death. For decades, we’ve used statins to lower cholesterol levels with modest effects, difficult adherence and unpredictable side effect profiles.
2003 brought the discovery of mutated PCSK9 in individuals with genetic hypercholesterolemia (high cholesterol). Healthy individuals express LDL-R in their liver, a receptor that removes LDL or “bad cholesterol” from the blood. This gain-of-function mutation causes PCSK9 to bind LDL-R and prevents it from clearing LDL, causing it to accumulate in the bloodstream and leading to higher incidence of cardiovascular disease.

The subsequent approval of two PCSK9 modulating antibodies roughly a decade later was one of the great translational triumphs of population genomics. These molecules, evolocumab and alirocumab, had Phase III data showing a ~60% reduction in blood cholesterol with only a monthly subcutaneous injection rather than some daily pill.
Our goal here is to retrace this process and build an antibody that binds to PCSK9. We are interested in engineering favorable translational properties, like low immunogenicity and high stability, and understanding clinical parameters, like dose and PK, for first-in-human injection.
We choose PCSK9 because it is a biologically convincing target, with a lucid mechanism and continued clinical relevance. There are dozens of PCSK9 inhibitors still in active development, including genetic medicines that offer potential cures. Similarly, we choose antibodies as a relevant therapeutic type with well understood development steps that generalize to many types of biologics.
The Anatomy of a Biotech
To walk through a development flow of an antibody, we must first understand the structure of our mock company and the function of each team. It is important to note not only what each team does but how they interface with each other.

Some of these teams can be mapped directly onto different stages of the drug development process and assume some rough chronological ordering.
1/ Antibody Discovery
Is responsible for taking the antibody “spec sheet”, eg. ideal target, disease, tissue, and producing the initial set of best-effort designs that will be further refined or tossed out.
They typically work with different types of high-throughput experiments, such as Hybridoma, phage display, transgenic animals or single B-cell, that test large libraries of variants under different selection pressures (usually binding affinity).
2/ Antibody Engineering
Takes the set of early designs from Discovery and modify them to have desirable therapeutic properties.
They use experiments like affinity maturation to improve binding but in general care about much more than constructing a sticky molecule. Binding affinity is probably the easiest property to engineer. Immunogenicity, stability, antigen-complex geometry (when antibodies bind, they can clump up in unintuitive ways) are all additional parameters they play with and are difficult to control.
3/ In Vitro Immunology
Takes the refined molecules from Engineering and look at “local” behavior like function, mechanism of action and early ADME characteristics.
They use cell based assays to measure antibody “function” - the effect of the antibody on death, growth, differentiation, etc. of a cell culture modeling the disease of interest. They will also validate the mechanism of action and ensure previously understood biomarkers of the disease are being modulated in a way consistent with how the drug is supposed to work.
4/ In Vivo Immunology
Puts the remaining drug candidates into animal models and test systemic properties that require intact organs and tissues, like immunogenicity, toxicity, PK.
At this stage, we are quite concerned both with safety and somehow arriving at the actual dose that will be used in the first cohort of patients. The latter is a difficult problem considering these models are just different organisms with distinct physiology (notably immune systems), yet mistakes estimating first-in-human dose cary very real consequences
5/ Clinical Development
Distills the learnings from the various translational step into an Investigational New Drug application and manages the logistics of human clinical trials, including coordinating patients, hospitals, drug manufacturing, etc.
The rest of these teams assume supporting roles and provide services to many of the teams throughout multiple stages of the drug’s lifecycle.
Molecular Biology
Responsible for manufacturing DNA “stuff” with assembly and cloning, eg. libraries of synthetic antibody DNA and phage vectors, engineering cell lines to stably express isolated antibody candidates, etc.
Computational Biology
Use a deep understanding of biology, statistics and data science to work closely with scientists to explore and understand experimental data. Often power users of R and/or Python.
Bioinformatics
Develop and maintain well-defined batched workflows that process raw experimental data into processed data suitable for human interpretation or secondary analysis. The common examples are the programs that process sequencing data.
AI/ML
Use statistical techniques to train models that predict the physical properties of antibody designs using a combination of public and in-house data.
The Lifecycle of an Antibody
It is also important to walk through the development stages themselves. We will do this briefly given the overlap with team function.

Target ID. Identify the molecule(s) that will have a therapeutic effect when we drug them.
Hit ID. Use screens to produce the initial set of drug candidates that will get gradually refined and filtered.
Hit-to-Lead. Filter, test, engineer this initial set with nice properties.
In Vitro Dev. Put antibodies in cell culture models. Focus on “local” drug properties like function and mechanism
In Vivo Dev. Put antibodies in animal models. Focus on systemic properties like safety, efficacy, PK. Last chance to figure how to dose real people (or if you should do this at all).
IND Filing. Convince the FDA you should put this antibody into a person. Use existing paperwork / data presentation “rails” when possible
Why Data Infrastructure
After deconstructing our mock company and walking through the major steps of a drug campaign, the difficulty of our task is becoming clear. A biotech is a complex human engineering projects with technical communication barriers and project-based siloes that pose new challenges to the free information flow necessary for scientific collaboration. These teams literally speak different languages, yet classically trained immunologists and machine learning engineers must somehow collaborate to engineer molecules.
To add even more complexity, the experiments needed to develop antibodies are also generating a lot of data. These high-throughput screens used by Discovery test 1e4-1e7 molecular variants and can generate GBs of sequencing data in a single experiment. We also need to combine these big experiments with smaller biochemical assays used by the Engineering, In Vitro or In Vivo teams, to build layered images of our drug and their effects on disease models, requiring structured data and metadata capture.
While a lion’s share of the complexity remains at the bench, industrial biotechnology is slowly becoming a discipline of information management. Clusters of computers, storage devices and new software tools, hereafter just data infrastructure, are the fit for purpose technology needed to manage this information. The adoption of these systems will do much to reverse Eroom’s law by productivity of every scientist by allowing them to understand their experiments faster.
The Components of a Data Infrastructure
We finally break down the pieces and design principles of a data infrastructure before moving into the actual steps of drug development. It is useful to start with what we are trying to do and work backwards rather than fixating on interesting properties of the tools.

The function of our system is to answer the question: Given one or more potentially very large experiments, do I understand the biological significance of my data? This task is deceptively complex and one might be surprised at the proportion of well funded and branded companies that are unable to answer this question across their research org in practice.
1/ Plots - Figures and Dashboards
Interactive software that visualize and explore data sits closest to biological insight and therefore our goal. They are used by scientists to draw final conclusions about experiments and produce figures that will be shared in publications or scientific decks.

“Plotting” is an oversimplified term to describe the complex systems that allow scientists to pull in data across multiple experiment types and timepoints, perform table arithmetic (eg. spreadsheet formulas, pivots), use statistical analysis and make interactive plots. This component is also used by those with the greatest experimental context but sometimes the least technical literacy, requiring extensive user testing and UX engineering.
Some ideal properties:
Ability to ingest processed outputs from all experiments over time using queries over structured metadata
Access to large computing resources to manipulate large objects, eg. matrices of counts
Perform operations on tables of values with either Python, graphical controls or natural language. Ability to convert between these.
Create and modify figures with either Python, graphical controls or natural language. Ability to convert between these.
2/ Pods - Exploratory Programming
The long tail of useful computational biology and bioinformatics work occurs in Jupyter notebook, RStudio and the terminal. This second component is a resizable computer with access to data and metadata from the rest of the teams.
Here computational scientists use *nix flavored tools to explore files, bioinformatics tools to marshal experimental outputs and data science libraries to explore data. In general, they write whatever code they need in their language of choice to do whatever they want.
Some ideal properties:
Access to all experimental data in a networked mount
Ability to pull in structured database tables into DataFrames
Ability to freeze environment and duplicate, share, resize
Access to sufficient computing resources on-demand
3/ Workflows - Bioinformatics
Bioinformatics workflows are the class of well-defined, batched programs that transform raw experimental data into processed outputs suitable for interpretation or secondary analysis. These programs generally run on clusters of large computers and move lots of file data around.

This third component is the orchestration system that executes these workflows. It provisions hardware, manages long running jobs, stores logs and handles errors. Graphical interfaces are needed to allow scientists to directly run and interpret the results of these workflows.
There are popular workflow DSLs, like Nextflow and Snakemake, that the bioinformatics community has adopted for scalable execution and portability to different cloud providers and infrastructure vendors. Many also prefer writing and maintaining these programs in Python.
Some ideal properties:
Ability to generate graphical interfaces that scientists will actually adopt
Resources defined in code provision sensible hardware during execution
Native support for Nextflow and Snakemake with portability to different execution “backends” (eg. AWS, GCP, LatchBio, Seqera)
Event-based automation triggered by file uploads from experimental machines
4/ Registry - Structured Schemas + Metadata Capture
The most overlooked fourth component of a data infrastructure are structured, typed schemas that capture different experimental data streams and associate them with wet lab metadata. This structure is what allows the long term re-use and synthesis of experiments. It is also necessary for the various “layers” previously mentioned, especially plotting.

Some ideal properties:
Ability to define and manipulate typed schemas in-code
Graphical representations of tables with strong UX and type specific error-validation to safely ingest values from scientists
Links directly with raw and large experimental data
Sync with existing LIMS, like Benchling, to prevent duplication of data
5/ Storage - Unstructured Objects
The last component is a general purpose object store that will scale with the pace of data generation at the bench.

Some ideal properties:
Graphical interface and file previews for scientific users
Ability to mount the entire system as a POSIX compliant filesystem on computers for exploratory programming
Versioning, provenance, durability, scalability
Developing an Antibody from Ideation to IND
Scientific Disclaimer
Complexity has been reduced and biological nuance lost in favor of clear communication and a digestible volume of material.
1/ Target Discovery
Usually the first development step is identifying and validating druggable “targets”, eg. molecules accessible to our antibody and of known association with disease. We are skipping this step because we already identified PCSK9 as our target and have confidence in its clinical viability.

2/ Hit Identification
Recall our goal at this stage is to generate an initial set of antibody designs that demonstrate modest binding affinity towards PCSK9. We will accomplish this in two steps, each involving two different clusters of teams.
Generating combinatorial libraries of antibody designs with AI/ML
Rather than relying on error-prone PCR or somatic hypermutation to generate essentially random libraries of sequences, AI/ML teams model the relationship between sequence and function to constrain antibody designs in-silico.
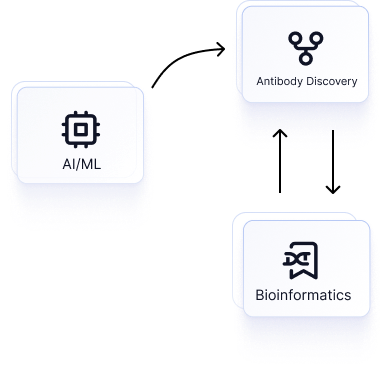
The AI/ML team first build and train machine learning models in Pods with their favorite frameworks, eg. pytorch, tensorflow, scikit. They generate an initial library of designs and upload them to structured, typed tables in Registry with Python.
This shared database table becomes the interface point with the Discovery team. Using a graphical view of the same database table that AI/ML manipulates in Python, they randomly sample the rows and manually inspect the designs, using their knowledge of sequence motifs and structural features to refine the AI/ML team’s initial batch of sequences.
Synthesizing Library, Cloning, Phage Display
When Discovery is satisfied with the library, the shared table in Registry is passed to Molecular Biology where they create an assembly plan for the sequences and order the necessary DNA components from their favorite vendor. After some Golden Gate to load antibody constructs onto vectors, Molecular Biology hands the vector library back to Discovery to run phage display.

Antibody Discovery preps the enriched pool of phage particles for NGS. Illumina machines stream sequencing reads directly to Storage, where automated Workflows developed by Bioinformatics process reads into tables of enriched counts upon upload from the sequencer. These counts tables are deposited into Registry along with information about the phage display experiment, eg. temperature, phage type, reagents, date and other information that might be useful later.
3/ Hit-to-Lead
Antibody Engineering is able to reach into Registry directly to explore the counts data. These scientists use Plots to query counts files by contextual metadata, like date, and make basic dashboards using natural language to rank order constructs by enrichment. They then select the top ranking constructs and run them through an affinity maturation process to increase their binding affinity.

4/ In Vitro Development
The PCSK9-LDL-R competition experiment is a great example of a cell-based functional assay. It measures the ability of our antibody candidates to block the interaction between PCSK9 and LDL-R. As we explored earlier, this leads to the therapeutic depletion of blood cholesterol.

In Vitro Immunology chooses a cell line with high LDL-R expression, like HepG2 liver cells, and co-cultures them with fluorescent PCSK9 and candidate antibodies. Using flow cytometry, they quantify the abundance of bound PCSK9 using fluorescence intensity.
The In Vitro team uploads raw flow data files to Storage and creates tables in Registry to associate flow files with metadata, critically the antibody candidate used in each experiment. Comp Bio is then able to create a dashboard in Plots to allow In Vitro Immunology, but really the entire company, to browse the functional data for each antibody candidate.
5/ In Vivo Development
One of the many experiments the In Vivo Immunology team might run is a rodent immunogenicity study to look for anti-drug antibodies (ADAs). The In Vivo team will inject a mouse with candidate antibodies, at a dosing regimen that mirrors the planned first-in-human dosing interval. They then run an ELISA plate using the PCSK9 antibody candidate itself to pan for ADAs.
This produces a small CSV of counts that are uploaded to Storage and hydrated with metadata in Registry. Similarly to the In-Vitro flow example, Comp Bio creates a dashboard in Plots to surface the immunogenicity to both In Vivo and the broader company. Everyone back through to Antibody Discovery can investigate crucial therapeutic properties of molecules they helped design.
6/ IND Filing
Every file and software tool - eg. bioinformatics program, Python library, R visualization framework, ad-hoc script - needs to be frozen and packaged into a “traceable data trail” suitable for FDA submission. This includes all of the plots, tables and small statistical analysis the scientists perform, and this set of assets are usually the most challenging to track down and clean.

This often under looked process can delay IND approval by months to years. The use of a central data infrastructure, tailor built for this filing procedure, allows Clinical Development to export this data in hours rather than months.
The Impact on Progress
Well designed and adopted data infrastructure create a “window” into the sum total of experimental data generated at a company over its lifetime. It allows everyone from the C-suite to an immunologist to an engineer to search for interesting data from historic experiments and understand what happened.
They allow scientists to go home with an interesting research question in mind and continue to feed their curiosity, by independently exploring, plotting, hypothesizing about data, much like a programmer is able to open up a laptop and burn the midnight oil completely on her own. This improves the economic productivity of each scientist and overall drug program efficiency.
By letting teams with very different backgrounds collaborate and share ideas that would otherwise be untenable, these systems not only lead to faster scientific insights but fundamentally new types of biological conclusions. The widespread adoption of these systems will materially improve the cost and speed of developing new medicines.
Latch is a modular and programmable data infrastructure designed to orchestrate diverse scientific teams for faster biological consensus.
Read more about the components:
Install this system, or just a single component, at your company.